
Figure 1. La structure JSON d’un article
Au cœur de CouchDB se trouve une structure de données appelée document. Pour mieux comprendre et utiliser CouchDB, vous devez penser documents. Ce chapitre vous guide à travers le cycle de vie des documents : de leur conception à leurs sauvegardes, nous passerons par leur consultation, leur agrégation et leur parcours au moyen des vues. Dans la section qui va suivre, vous verrez aussi comment CouchDB peut publier un document dans un autre format.
Les documents forment un ensemble de données autonomes. Vous avez peut-être déjà entendu parler du mot « tuple » pour indiquer quelque chose de semblable. Vos données sont souvent composées de types de données natifs tels que les entiers ou les chaînes de caractères. Les documents sont alors le premier niveau d’abstraction au-dessus de ces types de données natifs. Ils apportent une structure et regroupent de manière logique les éléments primitifs. Par exemple, la taille d’une personne peut être codée en tant qu’entier (176), mais cet entier fait souvent partie d’une structure plus vaste qui contient une étiquette ("taille": 176) et une donnée liée ({"nom":"Chris", "taille": 176}).
Le nombre d’éléments que vous stockez dans un document dépend avant tout de votre application, et aussi de la manière dont vous comptez utiliser les vues par la suite. En règle générale, un document correspond à peu de choses près à l’instance de l’objet correspondant dans votre langage de programmation. Dans le cas d’une boutique en ligne, vous aurez des objets, des ventes et des commentaires pour vos marchandises. Ce sont des candidats potentiels pour devenir des objets et, par conséquent, des documents.
Les documents se différencient subtilement des objets traditionnels, car ils appartiennent à des auteurs et permettent les opérations CRUD (pour Create, Read, Update, Delete, respectivement créer, lire, modifier, supprimer). Les logiciels de traitement de documents (comme votre logiciel de traitement de texte et votre tableur) ont conçu leur modèle de persistance des données autour du concept de document, ce qui permet aux auteurs de retrouver ce qu’ils ont écrit. De la même manière, dans une application CouchDB, vous pouvez vous réserver des marges de manœuvre vis-à-vis de la couche de présentation. Si, au lieu d’adjoindre automatiquement des estampilles temporelles (timestamps en anglais) à vos données, vous permettez à l’utilisateur de les saisir, vous obtenez par là même la possibilité de créer des brouillons qui ne seront publiés qu’une fois la date saisie atteinte. Pour cela, il suffit que votre vue utilise une endkey positionnée à now ; et cela ne vous a rien coûté !
Les fonctions de validation sont là pour vous éviter d’avoir à vous soucier de l’impact de données erronées. Dans la plupart des cas, un logiciel gérant des documents laisse le soin à l’application de modifier et de manipuler les données avant de les sauvegarder à nouveau. Tant que vous donnez à l’utilisateur le document qu’il vous a demandé de sauvegarder, il sera content.
Prenons le cas suivant : vous permettez à vos utilisateurs de rédiger un commentaire sur l’objet « livre sympathique ». Vous avez la possibilité de stocker ces commentaires dans un tableau au sein même du document de cet objet. Il est ainsi très simple de retrouver les commentaires de l’objet, mais, comme on dit, ça ne résiste pas au passage à l’échelle. En effet, un objet populaire peut avoir des dizaines, des centaines, voire des milliers de commentaires.
Aussi, plutôt que de stocker une liste de commentaires au sein même de l’objet, il serait ici préférable de les regrouper dans un recueil (en anglais, collection). CouchDB vous permet de parcourir aisément des recueils. Il est probable que vous désiriez n’en montrer qu’une dizaine ou une vingtaine à la fois et vouliez disposer de boutons « précédents » et « suivants ». En stockant individuellement les commentaires, vous pouvez les regrouper à l’aide des vues. Un groupe pourrait alors contenir tous les commentaires – ou des tranches de dix ou vingt –, le tout trié par rapport à l’objet auquel ils sont liés pour qu’il soit aisé de trouver le sous-ensemble dont vous avez besoin.
Par conséquent, une règle de base consiste à diviser en documents ce que vous gérerez individuellement dans votre application. Les objets sont unitaires, les commentaires sont unitaires, mais vous n’avez pas besoin de les redécouper. Les vues permettent de regrouper facilement vos documents de la manière qui vous intéresse.
Il est temps de concevoir notre application d’exemple pour vous montrer ce qu’il en est dans la pratique.
La première étape dans la conception de toute application, une fois que vous savez ce qu’est le programme et avez déterminé les interactions homme-machine, est de définir le format dans lequel vos données seront représentées et stockées. Notre blogue d’exemple est écrit en JavaScript. Un peu avant, nous avons dit que les documents représentent à peu près vos objets dans le langage que vous utilisez. Dans le cas présent, la correspondance est exacte. En effet, CouchDB a emprunté le format de données JSON à JavaScript ; ce qui nous permet d’exploiter les documents comme des objets natifs. C’est très pratique et nous évitent bien des problèmes. Si vous avez déjà travaillé avec un ORM (Object-Relational Mapping, Correspondance objet-relationnel), vous voyez quels soucis nous évoquons.
Concevons une structure JSON pour les articles du blogue. Nous savons que nous aurons besoin, pour chaque article, d’un auteur, d’un titre et d’un corps. Nous savons aussi que nous voulons utiliser l’identifiant du document pour le retrouver et ainsi faire plaisir aux moteurs de recherche. Et nous voudrions pouvoir les trier par date de rédaction.
Il devrait vous être facile de comprendrez comment JSON fonctionne. Les accolades ({}) cernent les objets, et ceux-ci sont des listes clé/valeur. Les clés sont formées par des chaînes de caractères qui sont délimitées par des guillemets doubles et droits (""). Enfin, une valeur peut être une chaîne, un entier, un objet ou un tableau ([]). Les clés sont séparées des valeurs par deux-points (:) et les couples clé/valeurs sont séparés par une virgule (,). C’est tout. Pour une description complète du format JSON, référez-vous à l’Annexe E, Introduction au JSON.
La Figure 1, La structure JSON d’un article illustre un document qui se conforme à nos exigences. Ce qui est bien, c’est que nous l’avons construit tout de suite ; c’est-à-dire que nous n’avons pas eu besoin de définir de schéma ni de préciser à quoi cela devait ressembler. Nous avons simplement créé un document contenant ce dont nous avons besoin. Et puisque les besoins liés au contenu des documents changent tout au long du processus de développement, il est aussi simple de stocker un nouveau document avec tous les champs correspondants au nouveau besoin.
Figure 1. La structure JSON d’un article
Ai-je la tête de quelqu’un qui a un plan ? Savez-vous ce que je suis ? Je suis un chien qui court après les voitures. Je ne saurais qu’en faire si jamais j’en attrapais une. Vous savez, je fais juste les choses. Le malin fait des plans, les policiers font des plans, Gordon fait des plans. Vous savez, ce sont des stratèges. Les stratèges tentent de contrôler leurs petits univers. Pour ma part, je ne suis pas un stratège. Je tente de démontrer aux stratèges combien leurs tentatives de contrôler les choses sont pathétiques.
—Joker, The Dark Knight : le chevalier noir
Attardons-nous un peu sur le document. Les deux premiers attributs (_id et _rev) sont là pour CouchDB et pour identifier une instance donnée du document. Pour _id, c’est facile : si je stocke quelque chose dans CouchDB, cela crée l’identifiant _id et me l’envoie dans la réponse. Je peux ensuite utiliser cet _id dans une URL qui m’enverra le document.
L’identifiant de votre document définit l’URL à laquelle le document pourra être récupéré par la suite. Si vous avez une base de données movies, tous les documents peuvent être trouvés sous l’URL /movies, mais où précisément ?
Si vous stockez un document qui a pour _id Jabberwocky ({"_id":"Jabberwocky"}) dans votre base de données movies, il sera accessible par l’URL /movies/Jabberwocky. Donc, si vous envoyez une requête GET à /movies/Jabberwocky, vous récupérerez la structure JSON qui forme votre document ({"_id":"Jabberwocky"}).
Le numéro de version _rev indique la version d’un document. Toute modification génère un nouveau numéro de version (inclus dans le document) et met à jour le champ _rev. C’est utile, car, quand vous sauvegardez un document, vous devez fournir un numéro de version à jour pour que CouchDB sache que vous avez travaillé sur la dernière version en date du document.
Nous en avons parlé dans le Chapitre 2, Cohérence finale. Le numéro de version agit comme un garde-fou pour les opérations d’écriture dans le contexte du système MVCC de CouchDB. Un document est une ressource partagée : plusieurs clients peuvent y lire et écrire au même moment. Pour garantir que deux écritures concurrentes ne vont pas interférer, chaque client doit fournir au serveur le numéro de version sur lequel s’appuient les changements. Si ce numéro correspond à celui stocké sur le disque, alors CouchDB acceptera la modification. Dans le cas contraire, la mise à jour sera rejetée. Le client doit alors récupérer la dernière version, y intégrer les modifications et sauvegarder à nouveau.
Ce mécanisme garantit deux choses : un client peut modifier uniquement une version qu’il connaît et ne peut pas interférer avec les modifications apportées par un tiers. Cela fonctionne sans que CouchDB ait à gérer de son côté le moindre verrou. On garantit ainsi qu’aucun client n’a à attendre qu’un autre client termine sa transaction. En outre, les mises à jour sont placées dans une queue, ce qui confère deux avantages : CouchDB ne tentera pas d’écrire plus vite que votre disque ; CouchDB ne pourra pas engager deux opérations d’écritures conflictuelles au même instant.
Maintenant que vous comprenez le rôle des attributs _id et _rev, regardons ce le reste.
{
"_id":"Hello-Sofa",
"_rev":"2-2143609722",
"type":"post",
La première chose que l’on trouve est le type de document. Notez qu’il s’agit d’un paramètre de niveau applicatif et qu’il n’a aucun impact sur CouchDB. En effet, de son point de vue, le type consiste simplement en un couple clé/valeur arbitraire. De notre point de vue, comme nous ajoutons des articles de blogue à Sofa, cela n’a guère plus de sens. En revanche, pour Sofa, le champ type détermine les fonctions de validations auxquelles le document doit être soumis. Il peut alors être certain que les documents de ce type, s’ils sont enregistrés dans Sofa, sont formatés correctement et peuvent être exploités par les vues et par l’interface utilisateur. De cette manière, l’on évite d’avoir à vérifier la présence des champs avant de les utiliser. C’est une approche purement conventionnelle, aussi pouvez-vous définir la vôtre ou déduire le type de document en fonction de sa structure (par ex., « contient un tableau avec trois cellules », ce qui est connu sous l’appellation anglaise de duck typing [NdT : le typage du canard fait référence à cette expression de James W. Riley : « si cela ressemble à un canard, nage comme un canard, cancane comme un canard, alors c’est probablement un canard »]). Nous espérons que cette explication vous convient.
"author":"jchris", "title":"Hello Sofa",
Les champs author et title sont définis quand l’article est créé. Le champ title field peut être modifié, mais le champ author est verrouillé par la fonction de validation pour des raisons de sécurité. Seul l’auteur d’un article peut l’éditer.
"tags":["example","blog post","json"],
Le système de tag de Sofa se contente de les stocker dans un tableau au sein du document. Ce genre de dénormalisation [NdT : au sens des bases de données] est une bonne approche avec CouchDB.
"format":"markdown", "body":"some markdown text", "html":"<p>the html text</p>",
Les articles de blogue sont rédigés au format HTML Markdown pour faciliter la vie de l’auteur. Le format Markdown, tel que saisi par l’utilisateur, est stocké dans le champ body. Juste avant que l’article soit sauvegardé, Sofa utilise le navigateur du client pour convertir ce champ en HTML. Il existe une fenêtre de prévisualisation du résultat de la conversion. De cette manière, vous pouvez vous assurer que le rendu correspond à ce vos vœux.
"created_at":"2009/05/25 06:10:40 +0000" }
Le champ created_at est utilisé pour trier les articles dans le flux Atom et sur la page d’accueil HTML.
La première page que nous devons créer pour obtenir un article dans notre blogue est celle qui permet de les créer et de les éditer.
L’édition est plus complexe que le simple affichage d’un article, ce qui signifie qu’à la fin de chapitre, vous aurez vu les techniques principales auxquelles nous recourrons par la suite.
La première chose à regarder est la fonction d’affichage (en anglais, show function) utilisée pour générer une page HTML. Si ce n’est déjà fait, consultez le Chapitre 8, Fonctions d’affichage pour assimiler les détails de l’API. Nous regarderons ici le code dans le contexte de Sofa, ce qui illustre comment les briques s’assemblent parfaitement.
function(doc, req) {
// !json templates.edit
// !json blog
// !code vendor/couchapp/path.js
// !code vendor/couchapp/template.js
La fonction d’affichage de la page d’édition de Sofa est assez simple. Dans la section précédente, nous avons montré l’importance des patrons et des bibliothèques que nous utilisons. La ligne importante est la macro !json qui charge le modèle de document edit.html qui se trouve dans le répertoire templates. Ces macros sont exécutées par CouchApp lorsque Sofa est déployé sur CouchDB. Pour plus d’informations sur les macros, référez-vous au Chapitre 13, Afficher des documents dans des formats particuliers.
// nous ne montrons que l’HTML
return template(templates.edit, {
doc : doc,
docid : toJSON((doc && doc._id) || null),
blog : blog,
assets : assetPath(),
index : listPath('index','recent-posts',{descending:true,limit:8})
});
}
Le reste de la fonction est simple. Nous remplissons le modèle de document avec les données extraites du document CouchDB. Si ce document n’existe pas, nous nous assurons de positionner docid à null. Cela nous permet d’utiliser le même modèle de document pour la création et l’édition d’articles.
La seule pièce manquante à l’échiquier est le code HTML nécessaire à sauvegarder un tel document.
Utilisez votre navigateur pour vous rendre sur http://127.0.0.1:5984/blog/_design/sofa/_show/edit et, avec votre éditeur de texte, ouvrez le code source du fichier templates/edit.html (ou consultez-le dans votre navigateur). Tout est paré ; la seule chose qui reste à faire est de relier le navigateur à CouchDB grâce au JavaScript. Reportez-vous à la Figure 2, Code HTML de edit.html.
Comme pour toute application web, la partie importante du code HTML est le formulaire qui permet de saisir les éditions. Ce formulaire permet de renseigner les informations basiques : le titre de l’article, le corps (au format Markdown), et les tags que l’auteur veut accoler au document.
<!-- form to create a Post -->
<form id="new-post" action="new.html" method="post">
<h1>Create a new post</h1>
<p><label>Title</label>
<input type="text" size="50" name="title"></p>
<p><label for="body">Body</label>
<textarea name="body" rows="28" cols="80">
</textarea></p>
<p><input id="preview" type="button" value="Preview"/>
<input type="submit" value="Save →"/></p>
</form>
Nous commençons avec un document HTML brut contenant un formulaire HTML. Nous utilisons ensuite JavaScript pour transcrire les données saisies par l’utilisateur en un document JSON et le sauvegarder dans CouchDB. Puisque nous nous intéressons à CouchDB, nous n’allons pas détailler le JavaScript ici. C’est un mélange de code applicatif propre à Sofa, d’assistants fournis par CouchApp et de jQuery pour la partie interface. Le principe, c’est que le navigateur capture le clic sur le bouton « Save » et applique des traitements avant d’envoyer le document résultant à CouchDB.

Figure 2. Code HTML de edit.html
Le code JavaScript qui gère la création et l’édition d’un article se concentre autour du formulaire HTML, comme l’indique la Figure 2, Code HTML de edit.html. Le greffon jQuery CouchApp permet quelques abstractions pour que nous puissions nous concentrer uniquement sur la manière dont le formulaire est transcrit en un document JSON lorsque l’utilisateur le soumet. $.CouchApp garantit aussi que l’utilisateur est authentifié et fournit les données de l’utilisateur à l’application. Référez-vous à la Figure 3, Délégations JavaScript pour edit.html.
$.CouchApp(function(app) {
app.loggedInNow(function(login) {
La première chose que nous faisons consiste à interroger la bibliothèque CouchApp pour nous assurer que l’utilisateur est authentifié. En considérant que la réponse est positive, nous affichons la page qui correspond à un éditeur. Cela signifie que nous adjoignons un gestionnaire d’évènement au formulaire et spécifions les fonctions auxquelles sera délégué le traitement du document, à la fois quand il sera chargé et quand il sera sauvegardé [NdT : une référence vers une fonction assurant une délégation est appelée callback function en anglais].

Figure 3. Figure 3, Délégations JavaScript pour edit.html
// w00t, we're logged in (according to the cookie)
$("#header").prepend('<span id="login">'+login+'</span>');
// setup CouchApp document/form system, adding app-specific callbacks
var B = new Blog(app);
Désormais, nous savons que l’utilisateur est connecté, aussi pouvons-nous afficher son nom d’utilisateur en haut de la page. La variable B est un raccourci vers un générateur de code propre à Sofa. Il contient des fonctions permettant, parmi d’autres choses, de convertir le corps de l’article du format Markdown à HTML. Nous avons placé ces fonctions dans le fichier blog.js afin d’éviter de les avoir dans le code principal.
var postForm = app.docForm("form#new-post", {
id : <%= docid %>,
fields : ["title", "body", "tags"],
template : {
type : "post",
format : "markdown",
author : login
},
L'assistant app.docForm() de CouchApp est une fonction permettant de définir la correspondance entre un document CouchDB et le formulaire HTML. Examinons les trois premiers arguments qui lui sont passés par Sofa. Tout d'abord, l'argument id indique à docForm() où sauvegarder le document ; dans le cas d'un nouveau document, il est positionné à « null ». En deuxième lieu, fields reçoit un tableau contenant les éléments du formulaire qui ont une correspondance directe avec les champs JSON du document CouchDB. Enfin, l'argument template reçoit un objet JavaScript qui sera utilisé comme point de départ dans le cas d'un nouveau document. Dans le cas présent, nous nous assurons que le type du document est « post » et que le format par défaut est « markdown ». Nous définissons aussi l'auteur pour qu'il corresponde au nom d'utilisateur de la session courante.
onLoad : function(doc) {
if (doc._id) {
B.editing(doc._id);
$('h1').html('Editing <a href="../post/'+doc._id+'">'+doc._id+'</a>');
$('#preview').before('<input type="button" id="delete"
value="Delete Post"/> ');
$("#delete").click(function() {
postForm.deleteDoc({
success: function(resp) {
$("h1").text("Deleted "+resp.id);
$('form#new-post input').attr('disabled', true);
}
});
return false;
});
}
$('label[for=body]').append(' <em>with '+(doc.format||'html')+'</em>');
La fonction déléguée onLoad est exécutée lorsque le document est chargé depuis CouchDB. Elle permet de mettre en forme le document avant de l'insérer dans le formulaire, ou encore d'agir sur d'autres éléments de l'interface utilisateur. Dans notre exemple, nous vérifions que le document possède déjà un identifiant. Si c'est le cas, cela signifie qu'il a déjà été sauvegardé. Aussi, nous pouvons ajouter un bouton pour le supprimer et y adjoignons une fonction déléguée pour traiter le clic. Tout cela semble exiger beaucoup de code, mais c'est, à la vérité, quelque chose de tout à fait traditionnel dans les applications Ajax. S'il y avait une critique à formuler à l'issue de cette section, ce serait de n'avoir pas déporté la logique liée à la création du bouton dans le fichier blog.js de manière à écarter les détails d'interface du code principal.
},
beforeSave : function(doc) {
doc.html = B.formatBody(doc.body, doc.format);
if (!doc.created_at) {
doc.created_at = new Date();
}
if (!doc.slug) {
doc.slug = app.slugifyString(doc.title);
doc._id = doc.slug;
}
if(doc.tags) {
doc.tags = doc.tags.split(",");
for(var idx in doc.tags) {
doc.tags[idx] = $.trim(doc.tags[idx]);
}
}
},
La fonction beforeSave() délègue à docForm le traitement suivant le clic sur le bouton de soumission. Dans le cas de Sofa, cette fonction positionne l'estampille temporelle (timestamp en anglais), dérive du titre un identifiant de document acceptable (pour obtenir de belles URL) et transforme la chaîne de caractères contenant les tags en un tableau. Elle se charge aussi de la conversion du format Markdown vers le format HTML de sorte qu'une fois le document sauvegardé, l'application accède directement à la forme HTML.
success : function(resp) {
$("#saved").text("Saved _rev: "+resp.rev).fadeIn(500).fadeOut(3000);
B.editing(resp.id);
}
});
La dernière fonction déléguée de Sofa se nomme success. On l'appelle dès que le document a été sauvegardé. Dans notre exemple, nous l'utilisons pour faire apparaître un message spontané à l'utilisateur qui lui indique le succès de l'opération ainsi qu'un lien pour consulter son article. De cette manière, lors de la création du document, vous pouvez immédiatement naviguer et obtenir le lien permanent vers l'article.
C'en est fait des fonctions déléguées utilisées dans docForm() !
$("#preview").click(function() {
var doc = postForm.localDoc();
var html = B.formatBody(doc.body, doc.format);
$('#show-preview').html(html);
// scroll down
$('body').scrollTo('#show-preview', {duration: 500});
});
Sofa dispose d'une fonctionnalité permettant d'avoir un aperçu des articles avant de les sauvegarder. Puisque cette dernière n'affecte pas la manière dont le document est sauvegardé, le code qui guette les évènements survenant sur le bouton « preview » n'est pas inclut dans docForm().
}, function() {
app.go('<%= assets %>/account.html#'+document.location);
});
});
Le dernier fragment de code ci-dessus est déclenché lorsque l'utilisateur n'est pas authentifié. Il se contente de rediriger l'utilisateur vers la page de connexion de sorte qu'il puisse s'identifier et tenter à nouveau d'éditer un article.
Désormais, vous savez comment le code précédent envoie un document JSON à CouchDB lorsque l'utilisateur clique sur « save ». Si c'est bien pratique pour créer une interface homme-machine, cela ne protège pas le moins du monde la base de données de mises à jour intempestives. C'est alors que la fonction de validation entre en scène. En effet, avec une fonction de validation adéquate, même un pirate opiniâtre ne pourra injecter de documents indésirés dans votre base. Regardons comment Sofa s'y prend. Pour plus de détails sur les fonctions de validation, référez-vous au Chapitre 7, Fonctions de validation.
function (newDoc, oldDoc, userCtx) {
// !code lib/validate.js
Cette ligne importe une bibliothèque de Sofa qui rend la suite bien plus lisible. En fait, c'est une simple classe enveloppante permettant de marquer une requête comme interdite (forbidden) ou non autorisée (unauthorized). Dans ce chapitre, nous nous sommes concentrés sur la fonction de validation, aussi notez bien qu'à défaut d'utiliser validate.js de Sofa, vous devrez travailler avec la logique plus primitive que fournit la bibliothèque.
unchanged("type");
unchanged("author");
unchanged("created_at");
Ces lignes font simplement ce qu'elles disent. Si les champs type, author ou created_at ont été altérés, une erreur est générée indiquant que la mise à jour est interdite. Notez que ces fonctions ne traitent pas le contenu de ces champs : elles stipulent que leur valeur ne doit pas changer d'une révision à l'autre.
if (newDoc.created_at) dateFormat("created_at");
L'assistant dateFormat garantit que la date, si elle est fournie, l'est au format attendu par les vues de Sofa.
// docs with authors can only be saved by their author
// admin can author anything...
if (!isAdmin(userCtx) && newDoc.author && newDoc.author != userCtx.name) {
unauthorized("Only "+newDoc.author+" may edit this document.");
}
Si celui qui sauvegarde un document est un administrateur, l'édition peut se faire. Dans le cas contraire, assurons-nous que l'auteur de l'article et celui qui l'édite présentement sont une seule et même personne. De cette manière, nous garantissons qu'un auteur peut modifier uniquement ses articles.
// authors and admins can always delete if (newDoc._deleted) return true;
Le bloc ci-dessous vérifie la validité des différents types de documents. Toutefois, comme les suppressions passent le contenu à _deleted: true, les critères ne pourront être satisfaits en cas de suppression ; c'est pourquoi les instructions sont court-circuitées par la condition ci-dessus.
if (newDoc.type == 'post') {
require("created_at", "author", "body", "html", "format", "title", "slug");
assert(newDoc.slug == newDoc._id, "Post slugs must be used as the _id.")
}
}
Au final, nous obtenons la fonction de validation d'un article. Dans celle-ci, nous exigeons la présence de certains champs, ce qui nous assure qu'ils seront là quand nous construirons nos vues et notre interface graphique.
Voyons comment tout cela s'emboîte ! Remplissez le formulaire avec quelques données de test et cliquez sur « save » pour obtenir la confirmation de la publication.
La figure 4, JSON encapsulé dans HTTP pour sauvegarder l'article montre la manière dont JavaScript a utilisé HTTP pour pousser (PUT) le document vers l'URL constituée du nom de la base de données et de l'identifiant du document. Elle illustre aussi la forme JSON du document envoyé dans le corps de la requête PUT. Si vous tentiez de récupérer ce document en forgeant une requête de type GET sur l'URL, vous verriez le même ensemble de données JSON avec, en plus, le champ _rev ajouté par CouchDB.
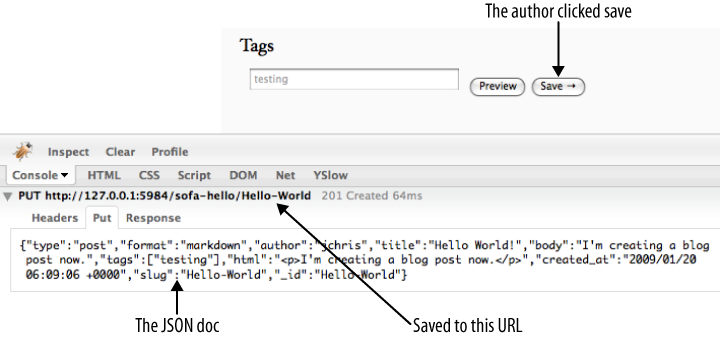
Figure 4. JSON encapsulé dans HTTP pour sauvegarder l'article
Vous pouvez aussi obtenir la version JSON du document que vous venez de sauvegarder à l'aide de Futon. Allez sur http://127.0.0.1:5984/_utils/database.html?blog/_all_docs et vous devriez voir un document avec un identifiant correspondant à celui de votre article. Cliquez dessus pour voir ce que Sofa a envoyé à CouchDB.
Nous avons expliqué comment définir les formats JSON pour votre application, comment garantir le respect de ceux-ci à l'aide des fonctions de validation, et avons vu les principes des mécanismes de sauvegarde des documents. Dans le prochain chapitre, nous verrons comment extraire des documents de CouchDB et les afficher dans le navigateur.