Figure 1. Le théorème de Brewer
Dans le chapitre précédent, nous avons vu que la flexibilité offerte par CouchDB nous permet de faire évoluer nos données comme notre application se développe et se métamorphose. Dans ce chapitre, nous verrons en quoi la granularité de CouchDB sert la simplicité et nous permet de bâtir aisément des systèmes distribués et échelonnables.
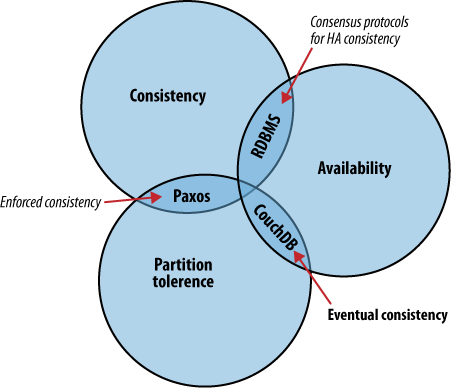
Un système distribué est un système robuste qui s’exécute au travers un vaste réseau. Une singularité de l’informatique distribuée tient en la possible disparition des liens réseau et il existe de nombreuses stratégies pour gérer ce type de segmentation. CouchDB se différentie en acceptant le principe de cohérence finale, par opposition à la garantie de cohérence absolue qui s’obtient au détriment de la disponibilité des données comme le font les SGDB relationnels ou Paxos. Ces systèmes ont de commun qu’ils considèrent que les données se comportent de manière différente quand plusieurs personnes y accèdent simultanément. Leur approche diffère selon qu’ils mettent l’accent sur la cohérence, la disponibilité ou la résistance au morcellement.
L’ingénierie des systèmes distribués est délicate. La plupart des pièges que vous rencontrerez au fil du temps ne sont pas évidents au départ. Nous n’avons pas toutes les solutions, et CouchDB n’est pas la panacée, mais quand vous travaillez avec la granularité de CouchDB plutôt que contre elle, vous pouvez naturellement concevoir des applications échelonnables.
Bien sûr, bâtir un système distribué n’est que le commencement. Un site web dont la base de données n’est accessible qu’une fois sur deux est à peu près inutile. Malheureusement, l’approche traditionnelle des bases de données relationnelles quant à la cohérence des données permet aux développeurs de s’appuyer sur un état global, sur des horloges globales et sur d’autres choses déconseillées car peu sûres, sans même s’en apercevoir. Aussi, avant de détailler la manière dont CouchDB promeut le passage à l’échelle, nous allons décrire les contraintes auxquelles un système distribué est confronté. Dès que nous aurons vu les problèmes qui se posent lorsqu’une application ne peut pas compter sur l’omniprésence de ses modules, nous verrons que CouchDB fournit un moyen intuitif et efficace pour modéliser des applications hautement disponibles.
Le théorème de Brewer définit quelques stratégies pour distribuer la logique applicative en différents points du réseau. CouchDB recourt au mécanisme de réplication pour propager les modifications entre les nœuds. C’est une approche très différente des algorithmes traditionnels et des bases de données relationnelles, lesquels placent le curseur à une autre intersection des courbes de cohérence, de disponibilité et de résistance au morcellement.
Le théorème de Brewer, illustré par la figure 1, Le théorème de Brewer, identifie trois problématiques distinctes :
Choisissez-en deux.
Figure 1. Le théorème de Brewer
Quand un système croît tant qu’un seul nœud de la base de données est incapable de gérer la charge, une solution censée est d’ajouter de nouveaux serveurs. Quand nous ajoutons des nœuds, nous devons nous interroger sur la répartition des données entre eux. Avons-nous des bases qui stockent exactement les mêmes données ? Mettons-nous différents jeux de données sur différents serveurs ? Laissons-nous uniquement certains serveurs écrire les données et d’autres se contenter de lire ?
Quelle que soit l’approche que l’on choisit, nous devrons nous confronter à un problème commun : conserver la synchronisation entre ces serveurs de base de données. Si vous écrivez quelque information sur un nœud, comment vous assurez-vous qu’une requête de lecture adressée à un autre serveur reflète ce dernier changement ? Ces évènements pourraient se succéder de quelques millisecondes. Même avec un petit nombre de serveurs, ce problème peut devenir d’une complexité extrême.
Lorsqu’il est absolument nécessaire que tous les clients accèdent à une vue cohérente des données, les utilisateurs d’un nœud devront attendre que tous les autres nœuds s’accordent avant de pouvoir effectuer l’opération de lecture ou d’écriture. Dans ce cas, nous voyons que la disponibilité subit le contrecoup de la cohérence. Cependant, il y a des situations dans lesquelles la disponibilité l’emporte sur la cohérence :
Tout nœud d’un système devrait pouvoir prendre des décisions en se basant uniquement sur l’état local. Si vous avez besoin de quelque chose, que vous êtes sous pression, que des problèmes se produisent, et que vous devez obtenir un accord, vous êtes perdu. Si vous vous préoccupez du passage à l’échelle, tout algorithme qui vous force à obtenir un accord deviendra inexorablement votre goulot d’étranglement. Soyez-en certain.
—Werner Vogels, Directeur de la technologie et Vice-président d’Amazon
Si la disponibilité est la priorité, nous pouvons laisser un client écrire sur un nœud de la base de données sans attendre l’accord des autres nœuds. Si la base de données est capable de réconcilier ces opérations avec les autres nœuds, nous obtenons une sorte de « cohérence finale » en échange de la haute disponibilité. Étonnamment, c’est un compromis souvent acceptable pour les applications.
À la différence des bases de données relationnelles, où chaque action effectuée est nécessairement sujette à des contrôles d’intégrité, CouchDB facilite la conception d’applications qui sacrifient la cohérence immédiate au profit de bien meilleures performances rendues possibles par une distribution simple.
Avant d’aborder le fonctionnement de CouchDB en cluster, il est important de comprendre le fonctionnement interne d’une seule instance de CouchDB. L’API CouchDB est conçue pour fournir une interface légère et pratique autour de la base. En regardant de plus près la structure du cœur de la base de données, nous aurons une meilleure compréhension de l’API qui l’entoure.
Au cœur de CouchDB se trouve un puissant moteur de stockage en B-Tree [NdT : arbre équilibré]. Un arbre B est une structure ordonnée qui permet la recherche, l’insertion et la suppression avec un temps de traitement logarithmique. Comme le montre la Figure 2, Anatomie d’une requête sur une vue, CouchDB utilise ce moteur de stockage en arbre B pour toutes les données, documents et vues. Si nous en comprenons un, nous les comprendrons tous.
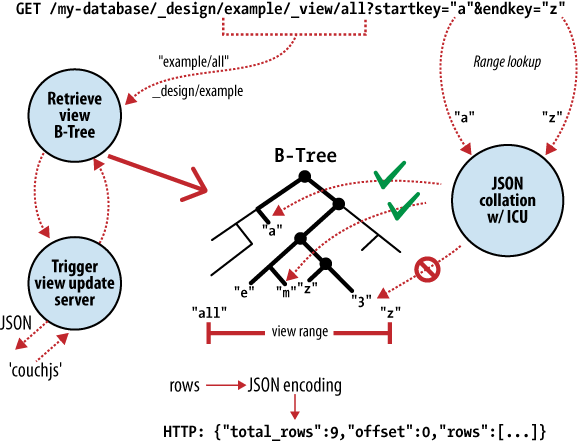
Figure 2. Anatomie d’une requête sur une vue.
CouchDB utilise MapReduce pour trouver les résultats d’une vue. MapReduce utilise deux fonctions : subdiviser [NdT : map] et agréger [NdT : reduce] qui sont appliquées sur chaque document indépendamment des autres. Être à même de séparer ces deux opérations induit que le calcul d’une vue peut être parallélisé et permettre le calcul incrémental. Plus important encore, ces deux fonctions produisent un couple (clé,valeur), ce qui permet à CouchDB de stocker les résultats dans l’arbre B, trié par clé. Or, les recherches par clé, ou intervalle de clés, sont d’une rapidité redoutable dans un arbre B. Traduit en notation de complexité (O), cela donne respectivement O(log N) et O(log N + K).
Avec CouchDB, nous accédons aux documents et aux vues par clé ou intervalle de clés. C’est une correspondance directe avec les opérations sous-jacentes effectuées par le moteur de stockage en arbre B de CouchDB. En joignant les insertions et mises à jour de documents, cette correspondance directe explique que nous parlions de fine couche d’interface entourant le moteur de base de données pour décrire l’API.
Être capable d’accéder aux enregistrements uniquement à l’aide de leur clé est une contrainte très importante qui nous permet d’obtenir des gains de performance impressionnants. En plus de ces gains colossaux de rapidité, nous pouvons répartir les données sur plusieurs nœuds sans perdre la faculté de requêter chaque nœud indépendamment. BigTable, Hadoop, SimpleDB et memcached restreignent l’accès aux objets par leur seule clé pour ces mêmes raisons.
Une table dans une base de données relationnelle est une seule structure de données. Si vous voulez modifier une table, disons mettre à jour un enregistrement, le SGBD doit garantir que personne ne peut lire cet enregistrement qui est en cours de mise à jour. Le moyen classique de garantir cette exclusivité est de recourir à un verrou. Si plusieurs clients veulent accéder à la table, le premier seulement obtient le verrou, ce qui place tous les autres en attente. Quand la requête du premier client s’achève, le verrou est donné au deuxième tandis que les autres patientent, et ainsi de suite. Cette exécution linéaire de requêtes, même quand elles parviennent en parallèle au serveur, gaspille une quantité importante de la capacité de traitement de votre serveur de base de données. Soumise à une charge importante, une base de données relationnelle peut passer davantage de temps à chercher qui est autorisé à faire quoi, et dans quel ordre, qu’à véritablement traiter les données.
Plutôt que de recourir aux verrous, CouchDB utilise le Multi-Version Concurrency Control (MVCC) pour gérer les accès concurrents à la base. La Figure 3, MVCC ne signifie aucun blocage illustre la différence entre MVCC et les mécanismes traditionnels de verrouillage. MVCC permet à CouchDB de tourner à plein régime, tout le temps, même soumis à une forte demande. Les requêtes sont exécutées en parallèle, exploitant à fond toute la capacité de calcul que le serveur peut offrir.
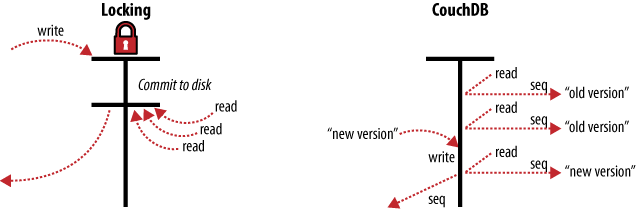
Figure 3. MVCC ne signifie aucun blocage.
Dans CouchDB, les documents sont versionnés, à peu près comme ils le seraient dans un système de gestion de version tel que Subversion. Si vous voulez changer une valeur dans un document, vous créez une toute nouvelle version de ce document et la sauvegardez par-dessus la première. Cela fait, vous vous retrouvez avec deux versions du même document, une ancienne et une nouvelle.
En quoi cela est-il meilleur que le verrouillage ? Considérez un ensemble de requêtes de lecture du document. La première requête accède au document. Pendant que cette lecture est traitée, une deuxième requête modifie le document. Puisque la deuxième requête inclut une toute nouvelle version de celui-ci, CouchDB peut simplement l’ajouter à la base de données sans avoir à attendre que la requête de lecture s’achève.
Au moment où une troisième requête arrive pour lire ce même document, CouchDB va l’orienter vers la nouvelle version du document qui vient d’être écrite. Pendant ce temps, la première requête peut toujours lire le document original.
Une requête de lecture accèdera toujours à la version la plus récente de votre base de données.
En tant que concepteurs d’applications, nous devons définir le type de données que nous acceptons en entrée et ceux que nous refusons. La faculté d’expression de ce type de validation sur des données complexes au sein même d’un tradionnel SGBD laisse à désirer. Heureusement, CouchDB offre, dans la base de données, une puissante fonctionnalité permettant de créer des formulaires de validation par document.
CouchDB peut valider les documents à l’aide de fonctions JavaScript semblables à celles utilisées pour MapReduce. Chaque fois que vous tentez de modifier un document, CouchDB va appeler la fonction de vérification avec une copie du document existant, une copie du nouveau document et un ensemble d’informations complémentaires telles que l’identifiant de l’utilisateur. La fonction de validation peut ainsi accepter ou refuser la modification.
En tirant profit de la granularité de CouchDB, nous épargnons d’innombrables cycles CPU qui auraient été nécessaires pour sérialiser les graphes d’objets provenant de SQL, pour les convertir en objets du domaine et en exploitant ces objets pour effectuer une validation au niveau applicatif.
Maintenir la cohérence au sein d’un unique nœud de base de données est relativement simple pour la plupart des bases. Les réels problèmes surviennent lorsqu’il s’agit de faire la même chose entre plusieurs serveurs. Si un client écrit sur le serveur A, comment s’assurer que c’est cohérent avec le serveur B, ou C, ou D ? Pour les bases de données relationnelles, c’est un problème complexe avec des livres entiers qui traitent du sujet. Vous pourriez utiliser des topologies de réplication multimaître, maître-esclave, partitionner, fragmenter, disposer des caches d’écriture et toutes sortes de techniques compliquées.
Puisqu’avec CouchDB les opérations s’effectuent toutes au niveau du document, si vous voulez utiliser deux nœuds, vous n’avez plus à vous inquiéter de les garder en communication permanente. CouchDB parvient à une cohérence finale entre les bases de données en recourant à la réplication incrémentale : un processus où les modifications des documents sont périodiquement copiées entre les serveurs. Nous sommes ainsi capables de construire un cluster dont les nœuds sont autosuffisants [NdT : shared-nothing cluster] et indépendants, ne laissant ainsi aucun point de contention dans le système.
Vous avez besoin d’absorber plus de charges avec un cluster CouchDB ? Il vous suffit d’ajouter un serveur.
Comme le montre la figure 4, Réplication incrémentale entre nœuds CouchDB, avec le mécanisme de réplication incrémentale, vous pouvez synchroniser vos données entre deux bases de données comme vous le voulez et quand vous le voulez. Après la réplication, chaque base de données est capable de travailler indépendamment.
Vous pourriez utiliser cette fonctionnalité pour synchroniser des serveurs dans un cluster ou entre vos centres de données à l’aide d’un programmateur de tâches tel que cron, ou encore avec votre ordinateur portable sur lequel vous travaillez dans le train. Chaque base de données peut être exploitée de manière classique et les modifications pourront être synchronisées ultérieurement dans les deux sens.
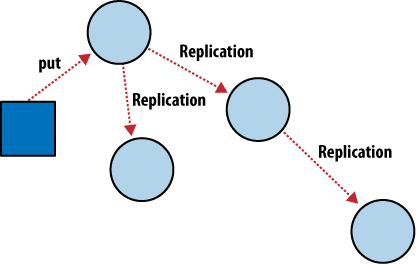
Figure 4. Réplication incrémentale entre nœuds CouchDB.
Que se passe-t-il quand vous modifiez le même document dans deux bases de données différentes et que vous voulez les synchroniser entre elles ? Le mécanisme de réplication de CouchDB est capable de détecter automatiquement les conflits et de les résoudre. Quand CouchDB détecte qu’un document a été modifié dans les deux bases de données, il y place un drapeau l’indiquant en conflit, comme le ferait un traditionnel système de gestion de version.
Ce n’est pas aussi problématique que cela pourrait le paraître. Quand deux versions d’un document sont en conflit à l’occasion de la réplication, la version gagnante est sauvegardée comme étant la nouvelle version. Plutôt que de jeter la version perdante, comme vous pourriez le penser, CouchDB la sauvegarde comme une version antérieure dans l’historique du document. Ainsi, il vous est possible d’y accéder si vous en avez besoin. Cela se produit automatiquement et de manière cohérente, donc les deux bases feront le même choix.
Il vous appartient de gérer les problèmes d’une manière qui ait du sens pour votre application. Vous pouvez laissez les choses telles quelles, ou revenir à la version antérieure, ou tenter de fusionner les deux versions et sauvegarder le résultat.
Greg Borenstein, un ami et collègue, a écrit une petite bibliothèque pour convertir les listes de lectures Songbird en objets JSON et a décidé de les stocker dans CouchDB pour les sauvegarder. Le logiciel final utilise MVCC de CouchDB et la gestion des versions de document pour garantir que les listes sont sauvegardées correctement entre les nœuds.
Songbird est un lecteur audiovisuel libre avec un navigateur intégré basé sur XULRunner de Mozilla. Songbird est disponible sur Microsoft Windows, Appel Mac OS X, Solaris et Linux.
Examinons le fonctionnement de cette application de sauvegarde. En premier lieu, du point de vue d’un utilisateur sauvegardant un seul ordinateur puis, ensuite, utilisant Songbird pour synchroniser les listes de lectures entre plusieurs ordinateurs. Nous verrons en quoi la gestion des versions des documents transforme un problème épineux en une solution qui fonctionne simplement.
La première fois que nous utilisons ce logiciel de sauvegarde, nous y chargeons nos listes de lectures et initialisons la sauvegarde. Chaque liste est convertie en un objet JSON qui est envoyé à la base de données CouchDB. Comme l’indique la figure 5, Sauvegarde vers une seule base de données, CouchDB retourne l’identifiant du document et le numéro de version [NdT : revision number] de chaque liste quand il le stocke dans la base.
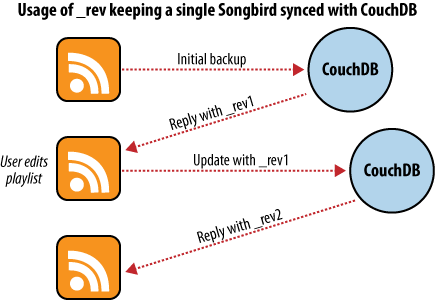
Figure 5. Sauvegarde vers une seule base de données.
Quelques jours plus tard, nous réalisons que nos listes de lecture ont été mises à jour et que nous voulons sauvegarder nos modifications. Après avoir chargé nos listes dans le logiciel de sauvegarde, celui-ci va chercher la dernière version présente dans CouchDB ainsi que son numéro de version. Quand le logiciel retourne la nouvelle liste, CouchDB requiert que ce document soit intégré à la requête.
CouchDB s’assure ensuite que le numéro de version du document correspond à celui présent dans la base. Celui-ci est toujours mis à jour à chaque modification, donc si le numéro indiqué par le client ne correspond pas à celui présent dans la base, cela signifie que quelqu’un l’a mis à jour entre temps. Modifier un document après que quelqu’un d’autre l’ait déjà fait est généralement une mauvaise idée.
Obliger les clients à fournir le bon numéro de version est le cœur de la stratégie optimiste de CouchDB en terme de concurrence d’accès.
Nous avons maintenant un ordinateur portable que nous voulons synchroniser avec notre ordinateur de bureau. Avec toutes nos listes de lectures sur notre bureau, la première étape consiste à restaurer la sauvegarde du bureau. C’est la première fois que nous le faisons, donc notre ordinateur portable est à présent à niveau avec celui du bureau.
Après avoir édité notre liste de tango argentin sur notre ordinateur portable pour y inclure de nouvelles musiques que nous avons achetées, nous voulons sauvegarder nos modifications. Le logiciel de sauvegarde remplace le document de la liste de lecture dans la base de données CouchDB du portable ; un nouveau numéro de version est généré. Quelques jours plus tard, nous nous souvenons de ces nouveaux morceaux et voulons les copier sur notre ordinateur de bureau. Comme le montre la figure 6, Synchronisation entre deux bases de données, le logiciel de sauvegarde copie le nouveau document et le nouveau numéro de version sur la base de l’ordinateur de bureau. Les deux bases de données sont désormais à niveau.
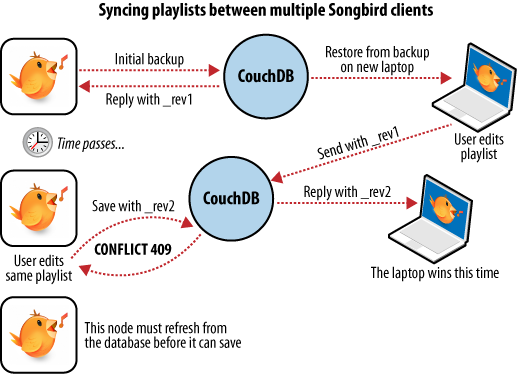
Figure 6. Synchronisation entre deux bases de données.
CouchDB garantit que ces mises à jour seront possibles uniquement si elles sont basées sur les informations courantes, car il conserve les différentes versions d’un document. Si nous avions fait des changements entre les deux synchronisations, les choses n’auraient pas été si simples.
Admettons que nous réalisions quelques changements sur nos listes du portable et oubliions de les synchroniser. Quelques jours plus tard, nous éditons les listes sur notre ordinateur de bureau, effectuons une sauvegarde et voulons la synchroniser avec le portable. Comme l’illustre la figure 7, Conflit de synchronisation entre deux bases de données, quand notre logiciel de sauvegarde tente de répliquer les deux bases de données, CouchDB se rend compte que les données envoyées par le bureau sont désuètes et nous informe qu’il y a eu un conflit.
Recouvrer de cette erreur est chose aisée d’un point de vue applicatif. Il suffit de télécharger la version de la liste de lecture et de permettre à l’utiliser de fusionner les modifications, ou de sauvegarder les modifications locales dans une nouvelle liste de lecture.
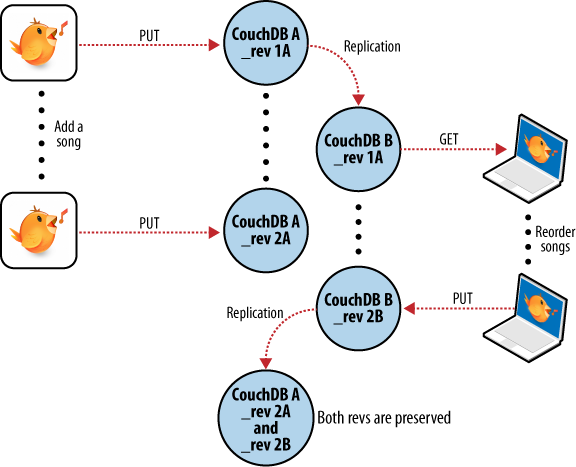
Figure 7. Conflit de synchronisation entre deux bases de données.
CouchDB s’inspire grandement de l’architecture du Web et des leçons apprises lors du déploiement de systèmes fortement distribués se basant sur celle-ci. En comprenant pourquoi cette architecture fonctionne comme cela et en apprenant à identifier quelles parties de votre application peuvent être facilement distribuées, mais aussi lesquelles ne le peuvent pas, vous améliorerez votre capacité à concevoir des applications distribuées et échelonnables, avec ou sans CouchDB.
Nous avons parcouru les principaux problèmes liés au modèle de cohérence de CouchDB et indiqué quelques bénéfices à en tirer quand vous travaillez dans le sens de CouchDB et non à son encontre. Mais voilà assez de théorie ! Démarrons l’engin et faisons fonctionner tout ça, qu’on voit de quoi il en retourne !