
Figura 1. Documentos contenidos en sí mismos (Self-contained documents)
Apache CouchDB pertenece a una nueva especie de sistemas de administración de baes de datos. Este capítulo explica por qué hay la necesidad de nuevos sistemas y las motivaciones detrás de CouchDB.
Como desarrolladores de CouchDB, naturalmente estamos excitados de estar usando CouchDB. En este capítulo compartiremos el por qué de nuestro entusiasmo. Te enseñaremos cómo el sistema schema-free de documentos de CouchDB es más apropiado para algunas aplicaciones, cómo el motor de consultas que viene dentro ofrece herramientas potentes para usar y procesar datos, y cómo el diseño de CouchDB se presta a la modularización y escalabilidad.
Si hay una palabra que describe a CouchDB, tiene que ser relax. Es el título de este libro, es el eslógan del logo oficial, y cuando arrancamos CouchDB vemos:
Apache CouchDB has started. Time to relax.
¿Por qué es tan importante la relajación? La productividad de los desarrolladores ha aumentado alrededor del doble en los últimos cinco años. El motivo principal son herramientas más potentes que a la vez son más fáciles de usar. Por ejemplo Ruby on Rails. Siendo un framework infinitamente complejo es al mismo tiempo fácil de empezar a usar. Éste es uno de los motivos por los que CouchDB es relajante: aprender CouchDB y entender sus conceptos esenciales debería de ser algo natural para cualquiera que haya trabajado en cosas Web. Y además también es fácil de explicar a gente no técnica.
Quitarse de en medio cuando alguien creativo está intentando construir una solución especializada es en sí mismo una caractrística fundamental y una cosa que CouchDB quiere hacer correctamente. Herramientas existentes nos han parecido demasiado pesadas a la hora de trabajar tanto en desarrollo como en producción, y hemos decidido concentrarnos en hacer CouchDB fácil, incluso un placer, de usar. Los capítulos 3 y 4 demostrarán la intuitiva REST API basada en HTTP.
Otra cosa relajante para los usuarios de CouchDB es la entorno de producción. Si tienes una aplicación en producción, CouchDB se preocupa, una vez más, de no molestarte. La arquitectura interna tolera fallos, y los errores se dan en un entorno controlado y se resuleven de manera apropiada. Problemas puntuales no afectan al servidor entero si no que permanecen aislados en una única consulta.
Los conceptos centrales de CouchDB son simples (pero potentes) y están bien estudiados. Los equipos de operaciones (si tienes un equipo; si no, eres tú) no tienen que temer comportamiento aleatorio o errores que no se pueden encontrar. Si algo sale mal, puedes averiguar fácilmente qué ha pasado-pero estas situaciones no se dan a menudo.
CouchDB también está diseñado para manejar tráfico variable. Por ejemplo, si una página web tiene un pico abrupto de tráfico, CouchDB normalmente absorbe muchas de las consultas concurrentes sin caerse. Probablemente lleve un poco más de tiempo procesar cada consulta, pero todas se responderán. Cuando el pico pasa, CouchDB vuelve a funcionar a su velocidad normal.
El tercer área de relajación se da a la hora de incrementar o reducir el hardware que da vida a tu aplicación. Normalmente nos referimos a esto como escalar un sistema. CouchDB impone una serie de limitaciones al programador. A primera vista, CouchDB parece inflexible, pero algunas cosas se han dejado fuera conscientemente simplemente porque si CouchDB las tuviera, permitirían al usuario crear aplicaciones que no escalan bien. Exploraremos el tema de escalar CouchDB en la Parte IV, “Deploying CouchDB”.
En resumen: CouchDB no te deja hacer cosas que te podrían meter en un problema más adelante. Esto a veces significa tener que desaprender prácticas y recomendaciones que hayas aprendido en tu trabajo actual o anterior. En el Capítulo 24, “Recetas” hay una lista de tareas comunes y cómo solventarlas en CouchDB.
Creemos que CouchDB cambiará radicalmente la manera en la construyes aplicaciones basadas en documentos. CouchDB combina almacenamiento intuitivo de documentos junto con un potente motor de consultas de una manera tan sencilla que probablemente te preguntes, “¿Por qué hasta ahora nadie había hecho algo así?”
Puede que Django esté hecho para la Web, pero CouchDB está hecho de la Web. Nunca he visto software que se ajuste tanto a la filosofía del HTTP. CouchDB hace que Django parezca old-school al igual que Django hace que ASP parecezca pasado de fecha.
—Jacob Kaplan-Moss, desarrollador de Django
El diseño de CouchDB toma muchas cosas de arquitectura web y de conceptos relacionados con los recursos, métodos y representaciones. Aumentándolos con potentes consultas, mapeado, combinación y filtrado de datos. Añádele escalabilidad, y replicación incremental, y CouchDB aparece como una solución ideal para bases de datos de documentos.
Escribimos software para mejorar nuestras vidas y las de otros. Normalmente esto supone tomar información mundana-como contactos, facturas, o recibos-y manipularlos usando una aplicación informática. CouchDB es una magnífica solución para aplicaciones comunes como éstas porque en el corazón, su modelo de datos se basa en esta idea natural de documentos contenidos en sí mismos, evolucionando en el tiempo.
Una factura contiene toda la información necesaria para describir una transacción en concreto-el vendedor, el comprador, la fecha, y una lista de artículos o servicios vendidos. Como podemos ver en la Figura 1, “Documentos contenidos en sí mismos (Self-contained documents)”, el papel de la factura no tiene ninguna referencia abstracta que apunte a otro papel con el nombre y la dirección del vendedor. Los contables agradecen la simplidad de tener todo en el mismo sitio. Y siendo una opción, los programadores también.
Figura 1. Documentos contenidos en sí mismos (Self-contained documents)
Aún así, en las bases de datos relacionales nos basamos precisamente en estas referecias para modelar los datos! Cada factura se salva como una fila en una tabla que hace referencia a otras tablas-una fila para la información del vendedor, una para el comprador, una para cada artículo facturado, y más filas para describir los artículos detalladamente, la información del fabricante y muchas cosas más.
No pretendemos ir en contra del modelo relacional, que es aplicable e increíblemente útil por varios motivos. Eso sí, esperamos ilustrar las situaciones en las que a veces los modelos no se ajustan a los datos de la misma manera en la que ocurren en el mundo real.
Echemos un vistazo a esta humilde base de datos de contactos para ilustrar una forma distinta de modelar datos, un forma en la que los datos se “ajusten” más a lo que representan en el mundo real-un montoncito de tarjetas de visita. Al igual que en ejemplo de la factura, una tarjeta de visita contiene toda la información que la describe, ahí mismo en la tarjeta. Ésto es lo que llamamos datos “contenidos en sí mismos” o “autocontenidos” (self-contained), y es un concepto muy importante a la hora de entender bases de datos de documentos como CouchDB.
La mayoría de las tarjetas de visita contienen más o menos la misma información-la identidad de alguien, una afiliación y algunos datos de contacto. La forma exacta de esta información puede variar en las tarjetas, pero la información representada en general se mantiene igual, y podemos fácilmente reconocer que es una tarjeta de visita. En este caso podemos describir una tarjeta de visita como un documento del mundo real.
La tarjeta de Jan puede tener un número de teléfono pero no tener fax, mientras que la de J. Chris incluye ambas. Jan no tiene que especificar el hecho de que no tiene fax diciendo algo ridículo como “Fax: Ninguno” en su tarjeta. El mero hecho de omitir el número de fax implica que no tiene.
Podemos ver que documentos del mismo tipo en mundo real, como tarjetas de visita, tienden a tener una semántica parecida-el mismo tipo de información-pero pueden variar sustancialmente en sintaxis, o cómo se estructura esa información. Los seres humanos manejamos con facilidad este tipo de variación.
Mientras que en una base de datos relacional traditional tenemos que modelar los datos de antemano, el diseño schema-free de CouchDB nos permite agregar los datos después del hecho, tal y como lo haríamos con documentos de verdad. En este libro veremos detalladamente cómo diseñar aplicaciones basadas en este paradigma de almacenamiento.
CouchDB es un sistema de almacenamiento útil en sí mismo. Se pueden construir muchas aplicaciones con las herramientas que te da CouchDB. Pero CouchDB está diseñado teniendo en cuenta un contexto más amplio. Sus componentes se pueden usar como piezas con las que construir soluciones a problemas de almacenamiento de forma ligéramente distinta en sistemas más grandes y complejos.
Tanto si necesitas un sistema lo más rápido posible y no te importa tanto la fiabilidad (imagínate logs), o uno que garantize almacenamiento en dos o más lugares geográficamente separados, y estás dispuesto a pagar una penalidad en rendimiento, CouchDB te permite construir estos sistemas.
Hay multitud de manecillas que podemos ajustar para hacer que un sistema funcione mejor en un área en particular, pero siempre afectaremos otro área al hacer cualquier ajuste. Un ejemlo es el teorema de CAP, que discutimos en otro capítulo. En las Figuras 2 y 3 podemos ver otros factores que afectan a los sistemas de almacenamiento.
Al reducir latencia en un sistema (lo cual es cierto no sólo en el caso de sistemas de almacenamiento), afectamos las capacidades de concurrencia y throughput.
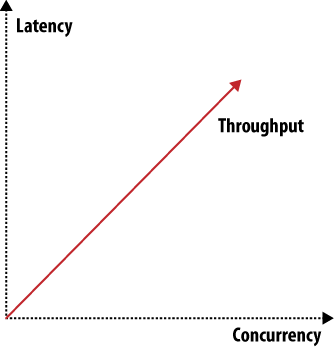
Figura 2. Throughput, latencia, o concurrencia
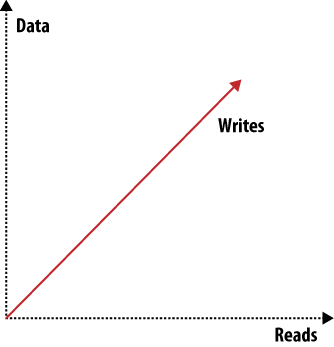
Figura 3. Escalando: consultas de lectura, consultas de escritura, o datos
Cuando queremos escalar hacia arriba, nos encontramos con tres problemas bien diferenciados: escalar consultas de lectura, consultas de escritura, o datos. Ortogonales a estos tres y a los elementos mostrados en las Figuras 2 y 3 hay muchos otros atributos como fiabilidad y simplicidad. Podemos dibujar muchos de estos gráficos para mostrar las diferentes características, y así la forma del sistema que describen.
CouchDB es muy flexible y nos da sufientes componentes para crear sistemas que se adapten a las necesidades del problema que tengamos que solucionar. Esto no quiere decir que CouchDB pueda amoldarse a cualquier problema-CouchDB no es la solución a todos los problemas-pero en el área del almacenamiento de datos, nos puede llevar lejos.
La replicación en CouchDB es una de estas piezas básicas. Su función fundamental es sincronizar dos o más bases de datos de CouchDB. Esto puede sonar simple, pero la simplicidad es la pieza clave para permitir que la replicación solvente varios problemas: sincronizar de manera fiable bases de datos entre múltiples máquinas para tener almacenamiento redundante; distribuir datos a un cluster de instancias de CouchDB que comparten un subconjunto del total de consultas que llegan a ese cluster (balance de carga); y distribuir datos entre lugares geográficamente distantes, como una oficina en Nueva York y otra en Tokio.
La replicación en CouchDB usa la misma REST API que todos los demás clientes. El protocolo HTTP es transparente y está estudiado en profundidad. La replicación funciona de forma incremental; esto es, que si cualquier cosa sale mal durante la replicación, como una desconexión de red, continuará donde se cortó la próxima vez que se ejecute. Del mismo modo, solamente transfiere los datos necesarios para sincronizar las bases de datos.
Una de las presunciones fundamentales de CouchDB es que las cosas pueden salir mal, la red se puede caer, y está diseñado para recuperarse de errores en vez de asumir que todo irá bien. El diseño incremental del sistema de replicación es lo que mejor representa esta idea. Las ideas detrás de “las cosas pueden salir mal” están materializadas en las Falacias de la Computación Distribuida:
Algunas herramientas existentes tratan de esconder el hecho de que hay una red y de que cualquiera de las condiciones anteriores o todas ellas pueden no darse en un sistema en particular. Esto normalmente resulta en errores fatales donde al final algo sale mal de verdad. En contraste, CouchDB no intenta esconder la red; soporta errores sin caerse y te permite intervenir cuando sea necesario.
CouchDB ha aprendido muchas lecciones de la Web, pero hay una cosa de la Web que se podría mejorar: la latencia. Cuando esperamos a que una aplicación responda o a que una página web se cargue, es casi seguro que estemos esperando a una conexión de red que no es lo rápida que quisiéramos en ese momento. Tener que esperar segundos en vez de milisegundos afecta notablemente a la experiencia de usuario y por ende a la satisfacción del mismo.
¿Qué hacer cuando no estás conectado? Pasa a menudo-tu proveedor de internet tiene problemas, o tu iPhone, G1, o Blackberry no tiene señal, y no tener conectividad significa que no hay forma de acceder a tus datos.
CouchDB también puede solventar este problema, y aquí el tema de escalar vuelve a ser importante. En este caso se trata de escalar hacia abajo. Imagínate CouchDB instalado en teléfonos y otros dispositivos que pueden sincronizar datos con una base de datos central cuando están conectados. La sincronización no se ve afectada por las limitaciones de una interfaz de usuario requeriendo tiempos de respuesta en rangos de milisegundos. Es más fácil ajustar un sistema para mayor ancho de banda y mayor latencia que para bajo ancho de banda y muy baja latencia. Las aplicaciones móviles pueden usar una instalación local de CouchDB para acceder a datos, y como no hay acceso remoto de red, la latencia por defecto es muy baja.
¿Se puede de verdad usar CouchDB en un teléfono? Erlang, el lenguage en el que CouchDB está implementado, ha sido diseñado para funcionar en dispositivos mucho más pequeños y menos potentes que un teléfono de hoy en día.
El capítulo siguiente continúa exporando la naturaleza distribuída de CouchDB. Por ahora deberíamos haberte dado lo necesario para despertar tu interés. !Ahí vamos!