Figura 1. El teorema CAP
En el capítulo anterior vimos como la flexibilidad de CouchDB permite que nuestra información evolucione mientras nuestra aplicación crece. En este capítulo exploraremos cómo "trabajar siguiendo la corriente" en CouchDB promueve simplicidad en nuestras aplicaciones y nos ayuda a construir sistemas escalables y distribuidos.
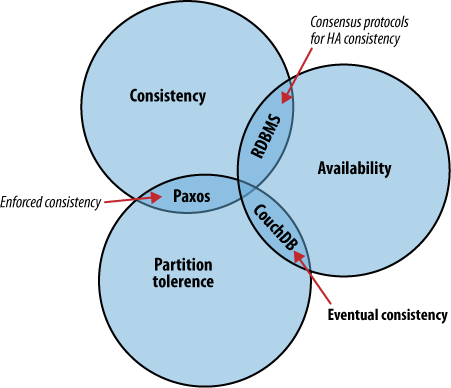
Un sistema distribuido es un sistema que opera robustamente sobre una red amplia. Una característica particular de redes en computación es que un enlace en la red puede potencialmente desaparecer, y hay varias estrategias para manejar este tipo de segmentación. CouchDB se diferencia de otras tecnologías por que acepta consistencia eventual, en contraste a dar prioridad a la consistencia absoluta sobre la disponibilidad, como RDBMS o Paxos. Lo que estos sistemas tienen en común es el entendimiento de que la información actúa diferentemente cuando mucha gente la accede en simultáneo. Su enfoque difiere en qué aspecto de consistencia, disponibilidad, o tolerancia en las particiones priorizan.
Diseñar sistemas distribuidos es difícil. Muchas de las trampas que vas a encontrar no son inmediatamente obvias. Nosotros no tenemos todas las soluciones, y CouchDB no es una panacea, pero cuando vas en el sentido de la corriente con CouchDB en vez de en contra, el camino de menos resistencia te lleva a crear aplicaciones naturalmente escalables.
Por supuesto, construir un sistema distribuido es sólo el principio. Un sitio web con una base de datos que solo está disponible la mitad del tiempo no tiene prácticamente ningún valor. Desafortunadamente, el enfoque tradicional sobre consistencia de bases de datos relacionales hace muy fácil que los programadores dependan del estado global y otros no-nos de alta disponibilidad, sin darse cuenta que lo están haciendo. Antes de examinar como CouchDB promueve escalabilidad, investigaremos las restricciones encontradas en sistemas distribuidos. Después de ver los problemas que aparecen cuando partes de tu aplicación no pueden confiar en estar en contacto constante entre ellas, veremos cómo CouchDB provee una manera intuitiva y útil para modelar aplicaciones de alta disponibilidad.
El teorema CAP describe diferentes estrategias para distribuir la lógica de una aplicación a través de redes. La solución de CouchDB usa replicación para propagar los cambios de la aplicación a través de los nodos participantes. Este es un enfoque fundamentalmente diferente que algoritmos de consenso y base de datos relacionales, los cuales operan en una intersección diferente de consistencia, disponibilidad y tolerancia en las particiones.
El teorema CAP, mostrado en la Figura 1, “The CAP teorema”, identifica tres preocupaciones distintas:
Escoge dos.
Figura 1. El teorema CAP
Cuando un sistema crece tan grande que un sólo nodo no es capaz de manejar la carga requerida, una solución razonable es añadir mas servidores. Cuando añadimos nodos tenemos que pensar cómo particionar la información entre ellos. ¿Tenemos varias bases de datos que comparten exactamente la misma información? ¿Ponemos diferentes partes de la información en diferentes servidores? ¿Solo dejamos que algunos servidores escriban la información y otros manejen la lectura?
Sin importar que enfoque tomemos, el problema que seguiremos encontrando es el de mantener todos los servidores de datos sincronizados. ¿Si escribes alguna información en un nodo, cómo vas a estar seguro de que una lectura en otro servidor refleja la nueva información? Estos eventos pueden estar separados por milisegundos. Aun con una colección modesta de servidores de datos este problema puede volverse extremadamente complejo.
Cuando es absolutamente crítico que todos los clientes vean una vista consistente de la base de datos, el usuario de un nodo tendrá que espera que los otros nodos estén en concordancia antes de poder leer o escribir en la base de datos. En este caso vemos que la disponibilidad queda relegada por la consistencia. Sin embargo, hay situaciones donde la disponibilidad triunfa sobre la consistencia:
Cada nodo en el sistema debería poder hacer decisiones basadas puramente en el estado local. Si tienes que hacer algo bajo alta carga con fallas ocurriendo y tienes que alcanzar concordancia, entonces estás perdido. Si te preocupa la escalabilidad, cualquier algoritmo que te fuerza a mantener concordancia será eventualmente el cuello de botella. Tómalo por sentado.
—Werner Vogels, Amazon CTO y Vice Presidente
Si la disponibilidad es una prioridad, podemos dejar a los clientes escribir la información en un nodo de la base de datos sin esperar que los otros nodos estén en concordancia. Si la base de datos sabe como reconciliar estas operaciones entre los nodos, logramos un tipo de 'consistencia eventual' a cambio de alta disponibilidad. Este es un compromiso sorprendentemente razonable para muchas aplicaciones.
A diferencia de bases de datos relacionales tradicionales, donde cada acción realizada está sujeta a verificaciones de consistencia en toda la base de datos, CouchDB hace muy simple construir aplicaciones que sacrifican consistencia inmediata a cambio de enormes mejoras de rendimiento gracias a la distribución.
Antes de que intentemos entender cómo CouchDB opera en un grupo, es importante que entendamos el funcionamiento interno de un solo nodo de CouchDB. La API de CouchDB está diseñada para proveer una capa delgada alrededor del núcleo de la base de datos. Al ver de cerca la estructura del núcleo de la base de datos, tendremos un mejor entendimiento de la API que lo rodea.
El corazón de CouchDB es un poderoso motor de almacenamiento de Árbol binario. Un árbol binario es una estructura de información ordenada que permite búsquedas, inserciones, y eliminaciones en tiempo logarítmico. Como ilustra la Figura 2, “Anatomía de una solicitud de vista”, CouchDB usa este árbol binario para toda los datos internos, documentos y vistas. Si entendemos uno, entenderemos todos.
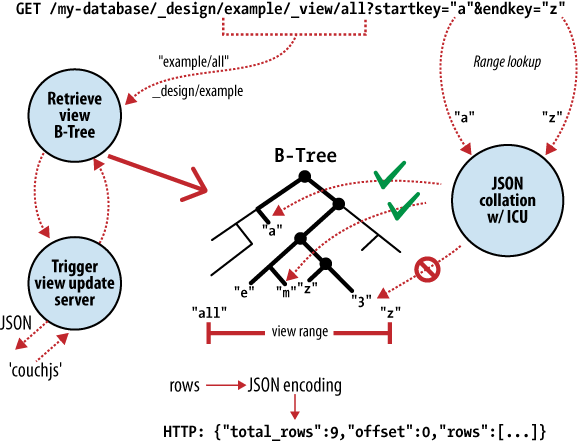
Figura 2. Anatomía de una petición de vista
CouchDB usa MapReduce para computar los resultados de una vista. MapReduce usa dos funciones, "map" y "reduce", que son aplicadas a cada documento de manera aislada. Poder aislar estas operaciones significa que procesar las vistas se presta a computación paralela e incremental. Aun más importante, debido a que estas funciones producen "pares" de llaves y valores (key/value pairs), CouchDB es capaz de insertarlas en el árbol binario, ordenadas por llave (key). Operaciones de búsquedas por llave o rango de llaves son extremadamente eficientes al usar un árbol binario, descrito en Big O notation como O(log N) y O(log N + K), respectivamente.
En CouchDB, accedemos a documentos o resultados de vistas usando llaves o rangos de llaves. Esto es una asignación directa a las operaciones subyacentes realizadas en el motor de almacenamiento de CouchDB. Junto con inserciones y modificaciones de documentos, esta asignación directa es la razón por lo que describimos el API de CouchDB como una envoltura delgada alrededor del núcleo de la base de datos.
Poder acceder a resultados sólo usando llaves es una restricción importante pero nos permite brindar enormes ganancias en rendimiento. Además de las mejoras masivas de velocidad, podemos particionar la información en múltiples nodos, sin afectar nuestra habilidad de consultar cada nodo en aislamiento. BigTable, Hadoop, SimpleDB, y memcached restringen la búsqueda de objetos usando llaves por exactamente las mismas razones.
Una tabla en una base de datos relacional es una sola estructura. Si quieres modificar una tabla — digamos, modificar una fila — la base de datos debe asegurarse que nadie más esté tratando de modificar esa fila y que nadie pueda leer esa fila mientras esté siendo modificada. La manera más común de manejar esto es usando lo que conocemos como un candado (lock). Si múltiples clientes quieren acceder a una tabla, el primer cliente obtiene el candado, haciendo esperar a los demás. Cuando la petición del primer cliente es procesada, el siguiente cliente obtiene el candado y así sucesivamente. Esta ejecución serial de peticiones, aún si llegan en paralelo, desperdicia una cantidad significativa de poder de procesamiento del servidor. Bajo alta carga, una base de datos relacional puede tomar más tiempo averiguando quién está autorizado a hacer qué, y en qué orden, que lo que toma hacer el trabajo real.
En vez de candados, CouchDB usa Control de Concurrencia multi-versión (MVCC en inglés) para manejar el acceso concurrente a la base de datos. La Figura 3, “MVCC significa no bloqueo ilustra las diferencias entre MVCC y mecanismos de bloqueo tradicionales. MVCC significa que CouchDB puede ejecutar a toda velocidad, todo el tiempo, inclusive bajo alta carga. Las solicitudes son ejecutadas en paralelo, haciendo excelente uso de hasta la última gota de poder de procesamiento que el servidor puede ofrecer.
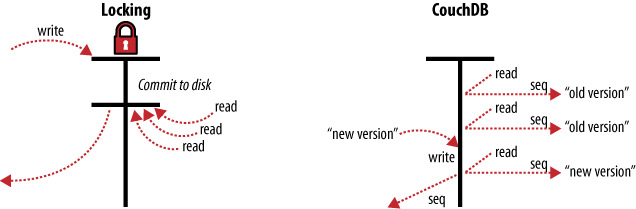
Figura 3. MVCC significa no bloqueo
Los documentos en CouchDB están versionados, tal como sucedería en un sistema de control de versiones normal como Subversion. Si quieres cambiar un valor en un documento, creas una nueva versión del documento y la salvas sobre la antigua. Después de hacer esto, terminas con dos versiones del mismo documento, una antigua y una nueva.
¿Cómo ofrece ésto mejoras sobre los candados? Considera un grupo de peticiones queriendo leer un documento. La primera solicitud lee el documento. Mientras está siendo procesada, una segunda petición modifica el documento. Dado que la segunda petición incluye una versión completamente nueva del documento, CouchDB puede simplemente añadirla a la base de datos sin tener que esperar a que termine la petición de lectura.
Cuando una tercera petición quiere leer el mismo documento, CouchDB apuntará a la nueva versión que acaba de ser guardada. Durante todo este proceso, la primera petición podría aún estar leyendo la versión original.
Una petición de lectura siempre obtendrá la versión más reciente de la base de datos.
Como desarrolladores de aplicaciones, debemos pensar en qué tipo de entradas debemos aceptar y cuáles debemos rechazar. El poder expresivo de hacer este tipo de validación sobre información compleja dentro de las bases de datos relacionales deja mucho que desear. Por suerte, CouchDB provee una poderosa manera de realizar validaciones por documento desde dentro de la base de datos.
CouchDB puede validar documentos usando funciones de JavaScript similares a las usadas en MapReduce. Cada vez que tratas de modificar un documento, CouchDB pasara a la función de validación una copia del documento existente, una copia del nuevo documento, y una colección de información adicional, como los detalles de autenticación del usuario. La función de validación tiene ahora la oportunidad de aprobar o rechazar la modificación.
Siguiendo la corriente y dejando a CouchDB hacer esto por nosotros, nos ahorramos una cantidad tremenda de ciclos de CPU que serían de lo contrario utilizados serializando gráficos de objetos de SQL, convirtiéndolos en objetos de nuestro dominio, y usando estos objetos para hacer validaciones en la aplicación.
Mantener la consistencia dentro de un solo nodo es relativamente fácil para la mayoría de las bases de datos. El problema real aparece cuando tratas de mantener la consistencia entre múltiples servidores de bases de datos. Si un cliente hace una operación de escritura en el servidor A, ¿cómo podemos estar seguros que éste es consistente con el servidor B, o C, o D? Para las bases de datos relacionales esto es un problema muy complejo, con libros enteros dedicados a su solución. Podrías usar múltiples maestros, maestro/esclavo, particionamento, sharding y toda clases de técnicas complejas.
Debido a que las operaciones en CouchDB ocurren dentro del contexto de un solo documento, si quieres usar dos nodos de base de datos, no te tienes que preocupar de que se mantengan en comunicación constante. CouchDB logra consistencia eventual entre las bases de datos usando replicación incremental, un proceso en que los cambios en los documentos son periódicamente copiados entre los servidores. Somos capaces de construir lo que se conoce como un grupo de bases de datos que comparten nada donde cada nodo es independiente y auto suficiente, sin dejar ningún punto de disputa a través del sistema.
¿Necesitas aumentar el tamaño de tu grupo de base de datos de CouchDB? Simplemente añade otro servidor.
Como está ilustrado en la Figura 4, “Replicación Incremental entre nodos de CouchDB”, con la replicación incremental de CouchDB, puedes sincronizar tu información entre dos bases de datos de como quieras y cuando quieras. Después de la replicación, cada base de datos puede trabajar independientemente.
Podrías usar esta funcionalidad para sincronizar servidores de bases de datos dentro de un grupo o entre data centers usando un programador de tareas como cron, o podrías usarlo para sincronizar la información con tu computadora portátil para trabajar sin conexión cuando viajas. Cada base de datos puede ser usada de la manera usual, y los cambios entre ellas pueden ser sincronizados después en ambas direcciones.
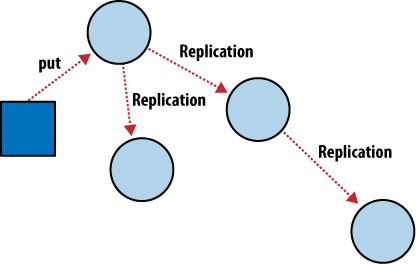
Figura 4. Replicación Incremental entre nodos de CouchDB
¿Qué sucede cuando modificas el mismo documento en dos bases de datos diferentes y luego quieres sincronizarlos? El sistema de replicación de CouchDB viene con detección y resolución automática de conflictos. Cuando CouchDB detecta que un documento ha sido cambiado en las dos bases de datos, marca el documento en conflicto, tal como pasaría en una sistema de control de versiones normal y corriente.
Esto no es tan problemático como suena inicialmente. Cuando dos versiones de un documento crean conflicto durante la replicación, la versión ganadora se salva como la versión más reciente en la historia. En vez de desechar la versión perdedora, como te lo esperarías, CouchDB la guarda como una versión anterior en la historia del documento, así que podrías acceder a ella si fuera necesario. Esto sucede automáticamente y de forma consistente, es decir que las dos bases de datos harán la misma elección.
Depende de ti manejar los conflictos de una manera que tenga sentido para tu aplicación. Puedes mantener las versiones elegidas de los documentos, revertir a versiones antiguas o tratar de combinar las dos versiones y guardar el resultado.
Greg Borenstein, un amigo y colega, escribió una pequeña librería para convertir listas de reproducción de Songbird a objetos JSON y decidió guardar estos objetos en CouchDB como parte de una aplicación de copia de seguridad. El software terminado usa el MVCC y revisión de documentos de CouchDB para asegurar que las listas de reproducción de Songbird sean copiadas robustamente entre los nodos.
Songbird es un programa gratuito para reproducir medios con un navegador integrado, basado en la plataforma XULRunner de Mozilla. Songbird está disponible para Microsoft Windows, Apple Mac OS X, Solaris, y Linux.
Examinemos el flujo de copia de seguridad de la aplicación, primero como un usuario haciendo una copia de seguridad desde una sola computadora, y luego usando Songbird para sincronizar las listas de reproducción entre múltiples computadoras. Veremos como las revisiones de documentos convierten lo que sería un problema complicado en algo que simplemente funciona.
La primera vez que utilizamos esta aplicación para hacer copias de seguridad, cargamos nuestras listas de reproducción a la aplicación e iniciamos la copia de seguridad. Cada lista de reproducción se convierte en un objeto JSON y se envía a una base de datos CouchDB. Tal como está ilustrado en la Figura 5, “Copiando a una sola base de datos”, CouchDB nos responde con el ID y revisión del documento salvado en la base de datos para cada lista de reproducción.
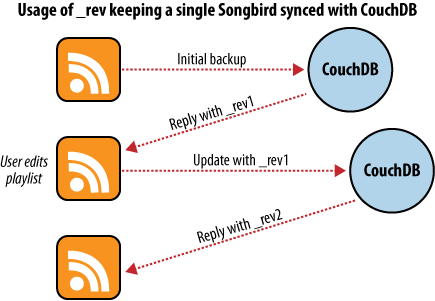
Figure 5. Copiando a una sola base de datos
Luego de unos días, encontramos que nuestras listas de reproducción han sido actualizadas y queremos hacer copias de seguridad de los cambios. Después de que cargáramos las listas de reproducción a la aplicación, ésta busca las últimas versiones de CouchDB, junto con las revisiones correspondientes. Cuando la aplicación envía de regreso el nuevo documento a CouchDB, CouchDB requiere que la revisión del documento se incluya en la petición.
CouchDB se asegura de que la revisión del documento recibida corresponda a la revisión actual en la base de datos. Debido a que CouchDB actualiza la revisión con cada modificación, si estos dos están desincronizados, esto sugiere que alguien más ha hecho cambios al documento en el lapso de tiempo que tomó hacer la petición del documento y el momento en que enviamos la actualización. Hacer cambios a un documento sin inspeccionarlo primero después que alguien lo ha modificado es una mala idea.
Forzar a los clientes a enviar la revisión correcta de los documentos es el corazón de la concurrencia optimista de CouchDB.
Tenemos una computadora portátil que queremos mantener sincronizada con nuestra computadora de escritorio. Con todas nuestras listas de reproducción en la computadora de escritorio, nuestro primer paso es 'restablecer desde la copia de seguridad' a nuestra computadora portátil. Ésta es la primera vez que hacemos esto, así que después nuestra computadora portátil debería tener una réplica exacta de la colección de listas de reproducción de nuestra computadora de escritorio.
Después de añadir algunas canciones a nuestra lista de reproducción de Tangos Argentinos en nuestra computadora portátil, queremos guardar nuestros cambios. La aplicación de copias de seguridad reemplaza el documento correspondiente en la base de datos CouchDB en nuestra computadora portátil, generando una nueva revisión del documento. Unos cuantos días después, recordamos las nuevas canciones y queremos copiar la lista de reproducción a nuestra computadora de escritorio. Como está ilustrado en la Figura 6, “Sincronización entre dos bases de datos”, la aplicación de copias de seguridad copia el nuevo documento con la nueva revisión a la base de datos CouchDB ubicada en la computadora de escritorio. Ambas bases de datos CouchDB tienen ahora la misma revisión del documento.
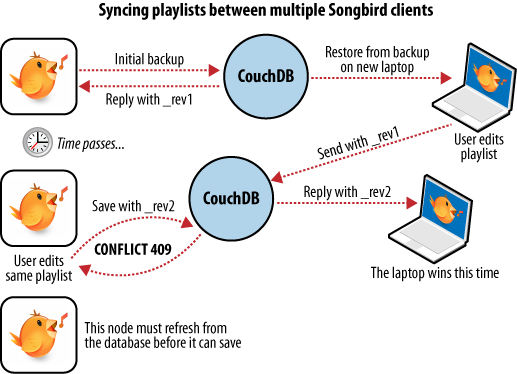
Figura 6 Sincronización entre dos bases de datos
Debido a que CouchDB lleva el rastro de las revisiones, se asegura que modificaciones como ésta funcionen solamente si están basadas en la información actual. Si hemos hecho modificaciones a las copias de seguridad de las listas de reproducción entre las sincronizaciones, las cosas no serán tan fáciles.
Hacemos algunos cambios en nuestra computadora portátil y nos olvidamos de sincronizar. Algunos días después estamos editando las listas de reproducción en nuestra computadora de escritorio, hacemos una copia de seguridad y queremos sincronizar esto a nuestra computadora portátil. Como está ilustrado en la Figura 7, Conflictos de Sincronización entre dos bases de datos”, cuando nuestra aplicación trata de replicar entre las dos bases de datos, CouchDB ve que los cambios enviados de nuestra computadora de escritorio son modificaciones de documentos desactualizados y amablemente nos informa que hay un conflicto.
Recuperase de este error es fácil desde la perspectiva de la aplicación. Simplemente descarga la versión de la lista de reproducción de CouchDB y provee una oportunidad para combinar los cambios o guarda las modificaciones locales a una nueva lista de reproducción.
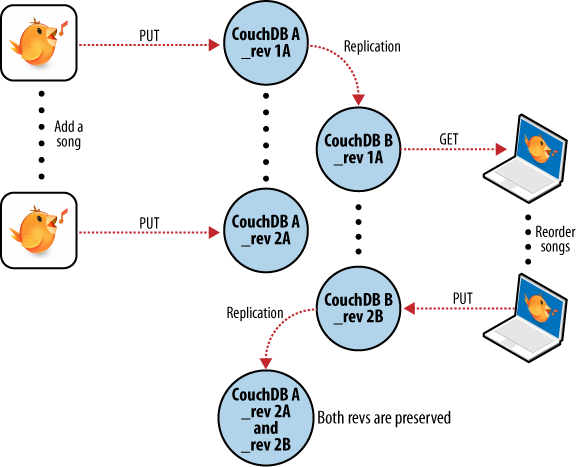
Figura 7 Conflictos de Sincronización entre dos bases de datos
El diseño de CouchDB toma prestado bastante de la arquitectura de la web y de las lecciones aprendidas al distribuir sistemas masivos en esa arquitectura. Al entender por qué esta arquitectura funciona en la forma que lo hace y al aprender a darse cuenta de qué partes de tu aplicación pueden ser distribuidas y cuales no, aumenta tu habilidad para diseñar aplicaciones distribuidas y escalables, con o sin CouchDB.
Hemos cubierto los problemas principales alrededor del modelo de consistencia de CouchDB y hemos visto algunos de los beneficios que podemos obtener cuando trabajamos con CouchDB y no en su contra. Pero suficiente teoría — empecemos a hacer algo y veamos a que viene el alboroto.