
Figur 1. Die Comments map Funktion
Views sind in verschiedenen Situationen nützlich:
Schauen wir uns die verschiedenen Szenarien etwas genauer an. Als erstes betrachten wir den Fall, indem Daten extrahiert und in eine bestimmte Reihenfolge gebracht werden müssen. Für eine Blogseite beispielsweise benötigen wir die Überschriften der Blog Postings sortiert nach Datum. Im Folgenden werden wir mit einigen Beispieldokumenten arbeiten, um zu zeigen wie Views funktionieren.
{
"_id":"biking",
"_rev":"AE19EBC7654",
"title":"Biking",
"body":"My biggest hobby is mountainbiking. The other day...",
"date":"2009/01/30 18:04:11"
}
{
"_id":"bought-a-cat",
"_rev":"4A3BBEE711",
"title":"Bought a Cat",
"body":"I went to the the pet store earlier and brought home a little kitty...",
"date":"2009/02/17 21:13:39"
}
{
"_id":"hello-world",
"_rev":"43FBA4E7AB",
"title":"Hello World",
"body":"Well hello and welcome to my new blog...",
"date":"2009/01/15 15:52:20"
}
Drei reichen für das Beispiel aus. Achten sie darauf, dass die Dokumente nach "_id" sortiert sind - so wie sie auch in der Datenbank gespeichert sind. Nun legen wir eine View an. In Kapitel 3: Der Anfang wurde gezeigt, wie man eine View in Futon, dem CouchDB Admin UI anlegt. Fangen wir zunächst mit etwas Code an:
function(doc) {
if(doc.date && doc.title) {
emit(doc.date, doc.title);
}
}
Das ist eine Map Funktion, die in JavaScript geschrieben ist. Falls sie wenig oder keine Erfahrung mit JavaScript, dafür aber mit C oder C-ähnlichen Sprachen wie Java, PHP oder C# haben, sollte das vertraut aussehen. Es ist eine einfache Funktionsdefintion.
Views werden in CouchDB als Strings im views Attribut eines Design Dokuments gespeichert. Man führt sie nicht selber aus, sondern wenn man die View abfragt, liest CouchDB den Source Code und führt ihn für jedes Dokument in der Datenbank, in der die View angelegt wurde, aus. Durch das Abfragen der View erhält man die View Ergebnismenge.
Alle Map Funktionen haben nur einen Parameter doc. Er enthält ein einzelnes Dokument der Datenbank. Unsere Map Funktion prüft, ob das Dokument ein date und ein title Attribut besitzt, was bei all unseren Dokumenten der Fall ist. Anschließend ruft die Map Funktion die eingebaute emit() Funtion mit diesen beiden Attributen als Argumenten auf.
Die emit() Funktion erwartet immer zwei Argumente: Zunächst den key (Schlüssel) und anschließend den value (Wert). Die emit(key,value) Funktion erzeugt einen Eintrag in der View Ergebnismenge. Man kann die emit() Funktion auch mehrfach in einer Map Funktion aufrufen, um mehrere Einträge in der Ergebnismenge zu erzeugen, doch darauf kommen wir später noch zurück.
CouchDB nimmt jeden Wert, den man der emit() Funktion übergibt und speichert ihn in einer Liste (siehe auch Tabelle 1: “View Ergebnismenge”). Jede Zeile in dieser Liste enthält einen Schlüssel und einen Wert. Was noch wichtiger ist: die Liste ist nach dem Schlüssel aufsteigend sortiert (in unserem Fall doc.date). Das ist die wichtigste Eigenschaft einer View. Ihr Ergebnis ist nach dem Schlüssel sortiert. Darauf werden wir immer wieder zurückkommen um noch andere nette Dinge zu tun.
| Key | Value |
|---|---|
"2009/01/15 15:52:20" | "Hello World" |
"2009/01/30 18:04:11" | "Biking" |
"2009/02/17 21:13:39" | "Bought a Cat" |
Tabelle 1: View Ergebnismenge
In den letzten Paragraphen haben wir folgenden Satz noch nicht beachtet : "Wenn man eine View aufruft, dann nimmt CouchDB den Source Code und führt diesen für jedes Dokument in der Datenbank aus." Wenn viele Dokumente in der Datenbank existieren, dann wird die Ausführung auf jedes Dokument sehr viel Zeit in Anspruch nehmen und man könnte meinen das dies sehr ineffizient ist. Ist es auch, aber CouchDB ist so aufgebaut, das dieser Mehraufwand nicht so stark ins Gewicht fällt: es werden alle Dokumente nur einmalig durchlaufen, dann, wenn die View das erste Mal aufgerufen wird. Wenn ein Dokument verändert wird, wird die Mapfunktion nur einmalig auf das Dokument angewandt um das Dokument mit den Keys und Values neu zu generieren.
Das View Ergebnis wird in einem B-Baum gespeichert, genau wie die Struktur, welche für das Halten der Dokumente verantwortlich ist. View B-Bäume werden in separaten Dateien gespeichert so, dass für High-Performance Zugriffe die CouchDB diese auf ihrer eigenen Festplatte hat. Die B-Bäume stellen eine sehr schnelle Ausführung von Lookups von Rows mittels Keys sicher. Genauso schnell ist die Suche nach Bereichen von Keys. In unserem Beispiel kann eine einzelne View alle Anfragen beantworten: "Gibt mir alle Blogposts von letzter Woche" oder "vom letzten Monat" oder "von diesem Jahr". Lies mehr über die Arbeit von CouchDB mit B-Bäumen im Anhang F, Die Macht der B-Bäume.
Wenn wir unsere View aufrufen, bekommen wir eine Liste aller Dokumente, sortiert nach Datum, zurückgeliefert. Jede Zeile besitzt einen Post-Titel so, dass wir Links zu Posts erstellen können. Tabelle 1: “View Ergebnismenge” ist dabei nur eine graphische Repräsentation. Das eigentliche Ergebnis ist formatiert in JSON und beinhaltet ein paar mehr Metadaten.
{
"total_rows": 3,
"offset": 0,
"rows": [
{
"key": "2009/01/15 15:52:20",
"id": "hello-world",
"value": "Hello World"
},
{
"key": "2009/02/17 21:13:39",
"id": "bought-a-cat",
"value": "Bought a Cat"
},
{
"key": "2009/01/30 18:04:11",
"id": "biking",
"value": "Biking"
}
]
}
Das richtige Ergebnis ist nicht so schön formatiert und enthält auch keine überflüssigen Leerzeichen und Zeilen, aber so ist es besser für uns das Ergebnis zu lesen und zu verstehen. Wo kommt die "id" Zeile her, vorher war diese nicht da? Diese war auch vorher da, aber wir hatten sie für das bessere Verständnis weggelassen. CouchDB erzeugt die Zeile mit der ID automatisch. Wir werden diese bei unseren Links zu den Blogposts auch einsetzen.
Das zweite Einsatzgebiet für views: “effiziente Indizies erstellen, um Dokumente mit beliebigem Wert oder Struktur zu finden.” Vorrangegangen wurden effiziente Indizies erklärt, aber es wurden ein paar Details übersprungen. Dies wird nun nachgehollt, bevor weiter auf map Funktionen eingegangen wird, da diese ein bisschen komplexer sind.
Als erstes, zurück zu den B-Bäumen! Es wurde schon erläutert, dass der B-Baum, welcher den nach den key´s sortiert wurde, nur einmal, beim ersten ausführen, erstellt wird. Alle weiteren Abfragen nutzen diesen temporär erstellten B-Baum für weitere Abfragen, anstatt erneut die map Funktion erneut auf alle Werte anzuwenden. Was passiert, wenn neue Dokumente hinzugefügt, bestehende geändert oder welche gelöscht werden ? Ganz einfach: CouchDB ist intelligent genug die neuen Einträge in den Views zu filtern. Diese werden als invalid markiert und nicht mehr in der View ausgegeben. Wenn ein Dokumente gelöscht wird, so wird in dem Ergebnis das betroffene Dokument nicht mehr angezeigt. Wenn das Dokument geändert wird, dann durchläuft die neue Version des Dokuments erneut die map Funktion und wird in dem Ergebnis automatisch an der richtigen Stelle einsortiert. Neue Dokumente werden genau so verarbeitet. Anhang F, Die Stärke der B-Bäume demonstriert das ein B-Baum eine sehr effiziente Struktur für die CouchDB ist, and the crash-only design of CouchDB databases is carried over to the view indexes as well.
Ein weiterer Punkt für Diskussion der Effizienz: in der Regel werden mehrere Dokumente zwischen den view Abfragen geändert. Der Mechanismus, des im vorigen erklärten Abschnittes, wird in einer Operation in der Datenbank ausgeführt so, dass die Resourcen besser genutzt werden und alles schneller abläuft.
Weiter zu komplexeren map Funktionen. Wir sagten, "Dokumente mit beliebigem Wert und Struktur in der Datenbank zu finden." Wir haben schon erläutert, wie man einen Wert aus einer sortierten Liste finden kann (Mittels des date Feldes). Der selbe Mechanismus wir für schnelles finden von anderen Daten genutzt. Die URI um eine View abzufragen lauet /database/_design/designdocname/_view/viewname. Dies gibt eine Liste von allen Werten in einer View zurück. Wir haben hier nur drei Dokumente so, dass alles sehr klein ist, aber mit tausenden von Dokumenten, kann diese Abfrage lange dauern. Man kann view parameters zu der URI hinzufügen hinzufügen um ein anderes Ergebnis zu erhalten. Wenn wir das Datum des blog Posts kennen, dann können wir danach suchen. Um ein einzelnes Dokument zu erhalten, können wir /blog/_design/docs/_view/by_date?key="2009/01/30 18:04:11" benutzen. So erhalten wir den "Biking" Blog Post. Beachte das man jedes erdenkliche Feld als key Parameter zu der emit() Funktion aufnehmen kann. Welches Feld auch immer genommen wird, danach kann sehr schnell gesucht werden.
Beachte das wenn mehrere Reihen die selben Felder haben (wenn eine view erstellt wird, wo ein Feld für den Namen des Post Autors genutzt wird), key Abfragen können mehr als eine Zeile zurückgeben.
Wir haben die Abfragen "alle Post des letzten Monats" bereits angesprochen. Wenn es jetzt Februar ist, dann würde die Abfrage so aussehen /blog/_design/docs/_view/by_date?startkey="2010/01/01 00:00:00"&endkey="2010/02/00 00:00:00". Der startkey und der endkey Parameter spezifizieren den Zeitraum in dem gesucht wird.
Um die Abfrage eleganter zu gestalten und für das weitere Kapitel nutzbarer zu machen, wird das Datumsfeld geändert. Anstatt einem String wird nun ein Array genutzt, bei dem die einzelnen Einträge Teil des Timestamps sind. Das klingt abwegig, ist aber ganz einfach. Anstatt von:
{
"date": "2009/01/31 00:00:00"
}
nutzen wir nun:
"date": [2009, 1, 31, 0, 0, 0]
Unsere map Funktion brauchen wir nicht zu verändern. Die Ausgabe der View sieht dafür ein wenig verändert aus. Table 2, “Das neue View Ergebnis”.
| Key | Value |
|---|---|
[2009, 1, 15, 15, 52, 20] | "Hello World" |
[2009, 2, 17, 21, 13, 39] | "Biking" |
[2009, 1, 30, 18, 4, 11] | "Bought a Cat" |
Table 2. Das neue View Ergebnis
Die Abfragen lauten nun /blog/_design/docs/_view/by_date?key=[2009, 1, 1, 0, 0, 0] und /blog/_design/docs/_view/by_date?key=[2009, 01, 31, 0, 0, 0]. All die Abwandlung ist nur eine Syntaxänderung, die Abfragenlokig wird dabei nicht verändert, aber dies zeigt die Mächtigkeit der Views. Man kann nicht ausschließlich einen Index mit skalaren Werten wie Strings und Integers nutzen, auch JSON Strukturen können als keys für die Views genutzt werden. Angenommen unsere Dokumente werden mit mehreren Tags versehen, welche wir in unserem Ergebnis sehen möchten, uns aber diejenigen Einträge, welche nicht getagt wurden, nicht interessieren.
{
...
tags: ["cool", "freak", "plankton"],
...
}
{
...
tags: [],
...
}
function(doc) {
if(doc.tags.length > 0) {
for(var idx in doc.tags) {
emit(doc.tags[idx], null);
}
}
}
Dies zeigt ein paar neue Dinge. Man kann anstatt von Werten auch Konditionen in die Strukturen einbauen (if(doc.tags.length > 0)). Dies ist auch ein Beispiel wie eine map Funktion, emit() mehrmals pro Dokument aufruft. Zudem kann auch null anstatt eines Wertes für den value Parameter genutzt werden. Dasselbe gilt für den key Parameter. Wir werden später sehen wie nützlich dieses Feature ist.
Um ein Ergebnis in umgekehrter Reihenfolge zu erhalten, kann man den descending=true Parameter nutzen. Wenn man gleichzeitig den startkey Parameter anhängt, gibt die CouchDB andere oder garkeine Spalten zurück.
Warum dies so ist, ist einfach zu verstehen wenn man weiß wie eine View Abfrage hinter den Kulissen arbeitet. Eine View ist einer Baum Struktur gespeichert, damit diese schnell ausgeführt werden kann. Wenn man eine View abfragt, dann arbeitet CouchDB so:
startkey angibt, zu lesen.endkey angegebenen, SpalteWenn descending=true genutzt wird, dann wird die Leserichtung verdreht, not aber die Sortierung der Spalten innerhalb der View. Nachfolgend wird das selbe Prinzip der zwei Schritte abgearbeitet.
Angenommen unser View Ergebnis sieht so aus:
| Key | Value |
|---|---|
0 | "foo" |
1 | "bar" |
2 | "baz" |
Eine potenzielle Abfragemöglichkeit sieht so aus: ?startkey=1&descending=true. Was wird die CouchDB tun ? Siehe oben bei Punkt 1: es wird beim startkey angefangen, welches die Spalte mit dem Key 1 ist und dann wird rückwärts bis ans Ende der View gelesen. Das Ergebnis sieht dann so aus:
| Key | Value |
|---|---|
1 | "bar" |
0 | "foo" |
Das ist nicht das was wir möchten. Um die Spalten mit den Indizies 1 und 2 in umgekehrter Reihenfolge zu erhalten muss einfach der startkey zum endkey abgeändert werden : endkey=1&descending=true:
| Key | Value |
|---|---|
2 | "baz" |
1 | "bar" |
Dann ist das gewünschte Ergebnis erreicht. CouchDB fängt am Ende der View an zu lesen und ließt bis zum Anfang oder bis der endkey erreicht wird.
Wir benutzen hier ein Array um den group_level Abfragenparameter zu unterstützen. CouchDB´s Views werden in B-Baum Strukturen gespeichert (was später im Detail weiter erläutert wird). Aufgrund der Struktur der B-Bäume, können die Zwischenergebnisse des Reduce Vorgangs einfach in den Knoten zwischengespeichert werden so, dass die Reduceabfragen, egal in welchem Bereich, immer in einer Logarithmischen Zeit laufen. Siehe Figur 1, “Die Comments map Funktion”.
In dem Blog nutzen wir group_level Reduceabfragen um die Anzahl der Comments für jeden Post, sowie die Anzahl aller Comments. Dies erreichen wir mit einer einzigen View über mehrere Methoden. Wir haben ein Array mit ein paar Keys, wobei wir annehmen, das jeder den Wert 1 hat:
["a","b","c"] ["a","b","e"] ["a","c","m"] ["b","a","c"] ["b","a","g"]
die Reduceview:
function(keys, values, rereduce) {
return sum(values)
}
gibt die Anzahl der Spalten zwischen den start und endkey zurück. Mit startkey=["a","b"]&endkey=["b"] (was die ersten drei, der oben stehenden keys beinhaltet) wäre das Ergebnis gleich 3, womit wir die Spalten gezählt haben. Wenn die Anzahl der Spalten zurückgegeben werden soll, ohne, dass es einen Zusammenhang zu der jeweiligen Spalte gibt, kann man einfach den rereduce Paramter benutzen:
function(keys, values, rereduce) {
if (rereduce) {
return sum(values);
} else {
return values.length;
}
}
Figur 1. Die Comments map Funktion
Das ist die Reduceview unserer Beispielanwendung um Comments zu zählen. Für die Ausgabe verwenden wir die Mapfunktion, was sinnvoller ist, anstatt Zeile für Zeile durchzugeben. Es kostet ein wenig Zeit mit den Map- und Reducefunktionen herumzuprobieren. Futon ist OK für diese Aufgaben, aber es erlaubt keinen vollen Zugriff auf alle Abfragenparameter. Eigene Abfragen in der präferierten Sprache zu schreiben, ist ein guter Weg den Hintergrund, sowie das MapReduce System von CouchDB zu verstehen.
Mittels der group_level Abfrage, werden automatisch mehrere Reduceabfragen über einen bestimmten Bereich ausgeführt: einer für jede group, welcher das level ausgibt in dem man abfragt. Hier nochmal die Keyliste von vorher, mit dem Grouplevel 1:
["a"] 3 ["b"] 2
Und mit group_level=2:
["a","b"] 2 ["a","c"] 1 ["b","a"] 2
Das Benutzen des group=true Parameters gleicht dem group_level=Exact Parameters. In diesem Fall wird jedem Key die Nummer 1 gegeben, da keine doppelten Keys vorhanden sind.
Im vorigen Abschnitt wurde kurz der rereduce Parameter angesprochen. Was es mit diesem auf sich hat, wird hier weiter erläutert. Bislang wissen wir, das die Viewergebnisse der Effizienz wegeb in einem B-Baum gespeichert werden. Die Existenz und das Nutzen des rereduce Parameters ist eng mit dem Arbeitsvorgang der B-Bäume verbunden.
Siehe das Mapergebnis in Beispiel 1, “Beispiel Viewergebnis (mmm, food)”.
"afrikan", 1 "afrikan", 1 "chinese", 1 "chinese", 1 "chinese", 1 "chinese", 1 "french", 1 "italian", 1 "italian", 1 "spanish", 1 "vietnamese", 1 "vietnamese", 1
Beispiel 1. Beispiel Viewergebnis (mmm, food)
Wenn man herausfinden möchte, wieviel Gerichte pro Land vorhanden sind, kann man die Reducefunktion welche wir im vorigen Abschnutt genutzt haben, wieder benutzen:
function(keys, values, rereduce) {
return sum(values);
}
Figur 2, “Der B-Baum Index” zeigt eine vereinfachte Version wie der Index eines B-Baum aussieht. Die Keystrings wurden hier gekürzt.
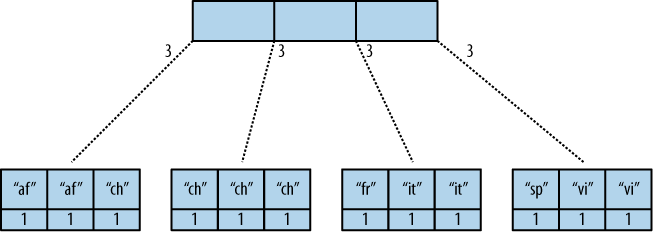
Figur 2, Der B-Baum Index
Das Viewergebnis ist, Informatikabsolventen nennen es einen Vordurchlauf durch die Baumstruktur. Gestartet von links, wird jedes Element und jeder Knoten betrachtet. Wenn ein Unterknoten existiert, dann wird dieser, genau wie der Hauptknoten, abgearbeitet. Wenn die gesamte Struktur durchlaufen wurde, ist der Vordurchlauf fertig.
CouchDB speichert sowohl die Schlüssel als auch die Werte in jedem Knoten. In unseren Fall ist es einfach, da es immer 1 ist, aber in anderen Fällen können alle Spalten auch unterschiedliche Werte haben. Wichtig ist, dass CouchDB alle Elemente, welche sich innerhalb eines Knoten in einer Reducefunktion befinden, (den rereduce Parameter auf false gesetzt) durchläuft und das Ergebnis in dem Elternknoten entlang der Ecke zu dem Unterknoten speichert. In diesem Fall ist der Wert jeder Ecke gleich 3. Dieser repräsentiert das Reduceergebnis für jeden Knoten der auf diese Ecke zeigt.
In der Realität besitzen Knoten mehr als 1600 Elemente. CouchDb berechnet die Ergebnisse aller Elemente in mehreren Operationen, nicht alle auf einmal. (Was desaströs für den Speicherverbrauch wäre).
Wir wollen jetzt wissen, wie viele "chinese" Einträge wir haben. Die Abfrageoption ist einfach: ?key="chinese".
Siehe Figur 3, “Das B-Baum Reduceergebnis”.
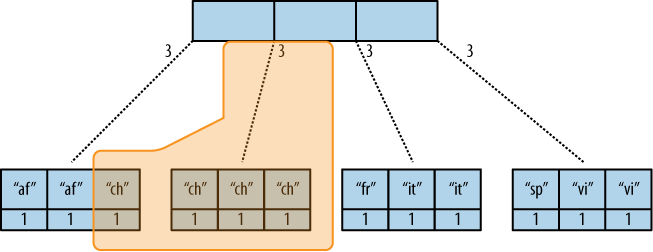
Figur 3. Das B-Baum Reduceergebnis
CouchDB erkennt das alle Werte in dem Unterknoten den "chinese" Key enthalten. Es werden genau 3 Werte gefunden, welche zur Berechnung des Endergebnisses genutzt werden. Danach wird der linke Knoten entdeckt, welcher auch den nötigen Schlüssel enthält, aber ausserhalb des angefragten Bereichs liegt (key= fragt einen Bereich, wo Anfang und Ende den selben Wert haben, an). Es werden die vorrangegangenen "chinese" Elemente, sowie die anderen Knotenelemente in der Reducefunktion genutzt. Wobei jetzt der rereduce Parameter auf true gesetzt wird.
Die Reducefunktion berechnet für das Abfrageergebnis 3 + 1 und liefert somit das gewünschte Resultat. Beispiel 2, “Das Ergebnis ist 4” zeigt mit Pseudocode den letzten Aufruf der Funktion.
function(null, [3, 1], true) {
return sum([3, 1]);
}
Beispiel 2. Das Ergebnis ist 4
Nun können wir sagen, das die Reducefunktion die Werte reduzieren muss. Wenn man sich einen B-Baum anschaut, sollte es offensichtlich werden, was passiert, wenn die Werte nicht reduziert werden. Weiter mit folgendem Mapergebnis und folgender Reducefunktion. Das Ergebnis soll eine Liste mit allen Labels sein, wobei jedes Label nur einmal vorkommen darf.
"abc", "afrikan" "cef", "afrikan" "fhi", "chinese" "hkl", "chinese" "ino", "chinese" "lqr", "chinese" "mtu", "french" "owx", "italian" "qza", "italian" "tdx", "spanish" "xfg", "vietnamese" "zul", "vietnamese"
Der Key ist hier egal und es wird eine Liste genommen, die alle existierenden Labels beinhaltet. Die Reducefunktion entfernt dann die Duplikate; siehe Beispiel 3, “Dies ist ein Beispiel was was produktiv nicht eingesetzt werden soll ”.
function(keys, values, rereduce) {
var unique_labels = {};
values.forEach(function(label) {
if(!unique_labels[label]) {
unique_labels[label] = true;
}
});
return unique_labels;
}
Beispiel 3. Dies ist ein Beispiel was was produktiv nicht eingesetzt werden soll
Dies erklärt Figur 4, “Ein überlaufenden Reduceindex”.
Wir hoffen, sie verstehen das Bild. Die Art, wie der B-tree Speicher arbeitet bedeutet, dass sie besser ihre Daten in der reduce Funktion reduzieren, damit nicht CouchDB große Mengen an Daten, linear wachsend, kopiert, falls nicht sogar schneller mit der Anzahl der Zeilen in der Ansicht.
CouchDB ist in der Lage das endgültige Ergebnis, bei einer view mit einer geringen Zeilen Anzahl, zu berechnen. Größere views hingegen brauchen nahezu unendlich lange um ein Ergebnis zu erzielen. Um dies zu vermeiden, schmeißt CouchDB (seit Version 0.10.0) dann einen Fehler, wenn ihre reduce Funktion nicht die eigenen input Werte reduziert.
Für Beispiele, wie man einzigartige Listen mit views berechnet, schauen sie sich Kapitel 21, View Cookbook for SQL Jockeys an.
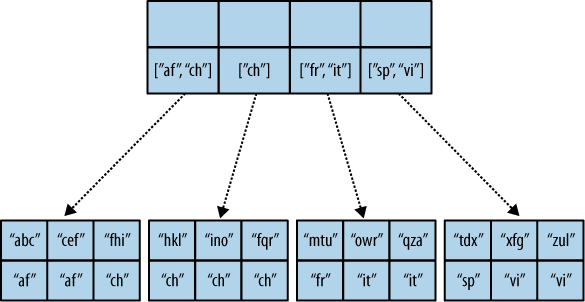
Figur 4. Ein überlaufenden Reduceindex
key Feld in der map Funktion verzichten, machen sie höchst wahrscheinlich einen Fehler.reduce Funktion einzigartig zu halten, machen sie höchst wahrscheinlich einen Fehler.Map functions are side effect–free functions that take a document as argument and emit key/value pairs. CouchDB stores the emitted rows by constructing a sorted B-tree index, so row lookups by key, as well as streaming operations across a range of rows, can be accomplished in a small memory and processing footprint, while writes avoid seeks. Generating a view takes O(N), where N is the total number of rows in the view. However, querying a view is very quick, as the B-tree remains shallow even when it contains many, many keys.
Reduce functions operate on the sorted rows emitted by map view functions. CouchDB’s reduce functionality takes advantage of one of the fundamental properties of B-tree indexes: for every leaf node (a sorted row), there is a chain of internal nodes reaching back to the root. Each leaf node in the B-tree carries a few rows (on the order of tens, depending on row size), and each internal node may link to a few leaf nodes or other internal nodes.
The reduce function is run on every node in the tree in order to calculate the final reduce value. The end result is a reduce function that can be incrementally updated upon changes to the map function, while recalculating the reduction values for a minimum number of nodes. The initial reduction is calculated once per each node (inner and leaf) in the tree.
When run on leaf nodes (which contain actual map rows), the reduce function’s third parameter, rereduce, is false. The arguments in this case are the keys and values as output by the map function. The function has a single returned reduction value, which is stored on the inner node that a working set of leaf nodes have in common, and is used as a cache in future reduce calculations.
When the reduce function is run on inner nodes, the rereduce flag is true. This allows the function to account for the fact that it will be receiving its own prior output. When rereduce is true, the values passed to the function are intermediate reduction values as cached from previous calculations. When the tree is more than two levels deep, the rereduce phase is repeated, consuming chunks of the previous level’s output until the final reduce value is calculated at the root node.
A common mistake new CouchDB users make is attempting to construct complex aggregate values with a reduce function. Full reductions should result in a scalar value, like 5, and not, for instance, a JSON hash with a set of unique keys and the count of each. The problem with this approach is that you’ll end up with a very large final value. The number of unique keys can be nearly as large as the number of total keys, even for a large set. It is fine to combine a few scalar calculations into one reduce function; for instance, to find the total, average, and standard deviation of a set of numbers in a single function.
If you’re interested in pushing the edge of CouchDB’s incremental reduce functionality, have a look at Google’s paper on Sawzall, which gives examples of some of the more exotic reductions that can be accomplished in a system with similar constraints.