Abbildung 1: Das CAP-Theorem
Im letzten Kapitel haben wir gezeigt, dass die Flexibilität von CouchDB es erlaubt, die Daten weiter zu entwickeln, während Anwendungen wachsen und sich ändern. In diesem Kapitel werden wir untersuchen, wie das Arbeiten mit CouchDB (anstatt gegen CouchDB) Einfachheit in den Anwendungen fördert und natürlich zu skalierbaren, verteilten Systemen führt.
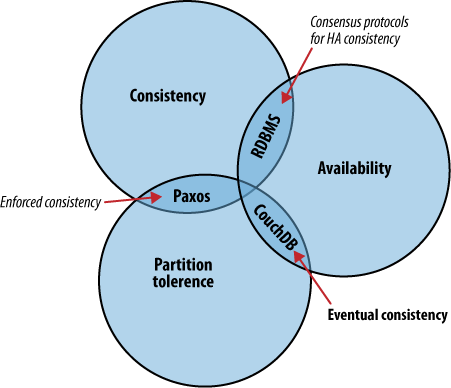
Ein verteiltes System ist ein System, welches zuverlässig über ein großes Netzwerk funktioniert. Eine spezielle Eigenschaft von Netzwerken ist, das Verbindungen jederzeit abbrechen können und es gibt viele Strategien wie man mit dieser Situation umgehen kann. CouchDB unterscheidet sich von anderen Systemen dadurch, dass es Eventual Consistency (die Daten sind letztendlich irgendwann konsistent) akzeptiert — im Gegensatz zu RDBMS und Paxos, die absolute Konsistenz über schlichte Verfügbarkeit stellen. All diesen Systeme ist gemein, dass sich Daten anders verhalten, wenn viele Leute gleichzeitig versuchen darauf zuzugreifen. Ihre Ansätze unterscheiden sich, wenn es um die Gewichtung von Konsistenz, Verfügbarkeit oder Partitionstoleranz geht.
Verteilte Systeme zu entwerfen ist nicht einfach. Viele der Stolperfallen, die mit der Zeit auftauchen, sind am Anfang nicht offensichtlich. CouchDB kennt nicht alle Antworten und es ist auch keine Allheilmittel. Wenn man jedoch mit CouchDB anstatt dagegen arbeitet, führen die so entwickelten Anwendungen automatisch zu skalierbaren Systemen.
Sicher ist die Entwicklung eines verteilten Systems nur der Anfang. Eine Webseite mit einer Datenbank ist nahezu nutzlos, wenn sie nur die Hälfte der Zeit erreichbar ist. Leider macht es der traditionelle Ansatz, Konsistenz mit Hilfe eines RDBMS sicherzustellen, den Entwicklern sehr leicht, sich auf einen globalen Zustand, synchronisierte Uhren und andere Dinge zu verlassen, die in hochverfügbaren Systemen nicht sichergestellt werden können. Meist tun sie das ohne sich dessen bewusst zu sein. Bevor wir untersuchen, wie CouchDB Skalierbarkeit fördert, schauen wir auf die Rahmenbedingungen von verteilten Systemen. Nachdem die Probleme offensichtlich werden, wenn Teile einer Anwendung sich nicht mehr darauf verlassen können, auf andere Teile ständig zugreifen zu können, wird deutlich, wie CouchDB einen intuitiven und sinnvollen Weg weist, um hochverfügbare Anwendungen zu entwickeln.
Das CAP-Theorem (CAP = Consistency, Avalability, Partition Tolerance) beschreibt einige Strategien um Anwendungslogik über ein Netzwerk zu verteilen. CouchDB verwendet Replikation um Änderungen zwischen den einzelnen Knoten zu synchronisieren. Das ist ein fundamental anderer Ansatz als der von Konsens-Algorithmen und relationalen Datenbanken, die an anderen Schnittpunkten von Konsistenz, Verfügbarkeit und Partitionstoleranz liegen.
Das CAP-Theorem in Abbildung 1: Das CAP-Theorem identifiziert drei separate Bereiche:
Wähle zwei aus.
Abbildung 1: Das CAP-Theorem
Wenn ein System so groß wird, dass ein einzelner Datenkbank Server nicht mehr in der Lage ist, die Last zu bewältigen, ist eine sinnvolle Lösung mehr Server hinzuzufügen. Mehrere Server bedeuten jedoch, dass die Daten zwischen den Servern partitioniert werden müssen. Haben einige wenige Datenbank Server immer exakt die gleichen Daten? Haben verschiedene Datenkbank Server verschiedene Teile der Daten? Soll auf manchen Servern nur geschrieben und von den anderen nur gelesen werden?
Egal welchen Ansatz man wählt, das eigentliche Problem, wie all diese Server synchronisiert werden, bleibt bestehen. Wie stellt man sicher, dass wenn man etwas in einen Knoten schreibt, der andere Knoten beim Lesen die neusten Daten liefert? Die Zugriffe können nur Millisekunden auseinander liegen. Selbst mit einer kleinen Anzahl von Datenkbank Servern kann dieses Problem sehr komplex werden.
Wenn es erforderlich ist, dass alle Nutzer eine konsistente Sicht auf die Datenbank haben, dann müssen die Nutzer des einen Knotens darauf warten, bis alle anderen Knoten sich synchronisiert haben, bevor sie wieder lesen oder schreiben können. In diesem Fall muss die Verfügbarkeit hinter die Konsistenz zurücktreten. Es gibt aber auch Fälle in denen Verfügbarkeit wichtiger ist als Konsistenz:
Jeder Knoten in einem System sollte in der Lage sein Entscheidungen zu treffen, die ausschließlich auf dem lokalen Zustand basieren. Wenn man etwas unter großer Last machen muss während gleichzeitig Fehler auftreten und man muss auf die Synchronisation warten, hat man verloren. Wenn Skalierbarkeit wichtig ist, wird jeder Algorithmus, der eine Synchronisierung erzwingt, irgendwann zum Flaschenhals werden. Nimm das als gegeben an.
—Werner Vogels, Amazon CTO und Vice President
Wenn Verfügbarkeit Priorität hat, können wir Clients die Daten zunächst auf einen Knoten schreiben lassen, ohne darauf zu warten, dass die anderen Knoten synchronisiert werden. Wenn die Datenbank weiß, wie sie mit dieser Situation umzugehen hat, sind die Daten irgendwann „letztendlich konsistent“ — allerdings unter Aufgabe der Hochverfügbarkeit der Daten. Für viele Anwendungen ist das ein erstaunlich guter Kompromiß.
Im Gegensatz zu traditionellen relationalen Datenbanken, bei denen jede Aktion notwendigerweise Konsistenzprüfungen über die ganze Datenbank nach sich ziehen, macht es CouchDB sehr einfach Anwendungen zu bauen, die sofortige Konsistenz gegen eine große Steigerung der Performanz eintauschen, welche durch einfache Verteilung zustande kommt.
Bevor wir versuchen zu erklären, wie CouchDB in einem Cluster funktioniert, ist es wichtig zu verstehen, wie ein einzelner CouchDB Knoten arbeitet. Das CouchDB API wurde so entworfen, dass es nur eine dünne Schicht über dem eigentlichen Datenbankkern ist. Indem man genauer auf die Struktur dieses Kerns schaut, versteht man das API, das ihn umgibt, besser.
Das Herz von CouchDB ist eine mächtige B-Tree Storage Engine. Ein B-Tree ist eine sortierte Datenstruktur, welche Suchen, Einfügen und Löschen von Knoten in logarithmischer Zeit erlaubt. Wie Abbildung 2: Anatomie eines Lesezugriffs zeigt, benutzt CouchDB die B-Tree Storage Engine für sämtliche internen Daten, Dokumente und Views. Hat man einen verstanden, versteht man alle.
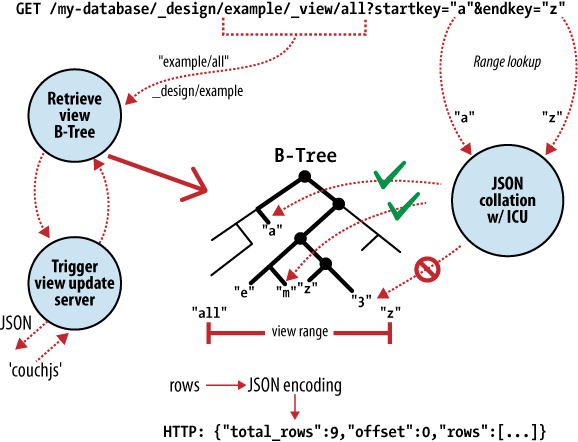
Abbildung 2: Anatomie eines Lesezugriffs
CouchDB verwendet MapReduce um die Ergebnisse einer View zu berechnen. MapReduce benutzt dazu zwei Funktionen „map“ und „reduce“, welche auf jedes Dokument separat angewendet werden. Die Möglichkeit diese Operationen zu isolieren führt dazu, dass man sie parallel und inkrementell ausführen kann. Wichtiger noch, weil diese Funktionen Key/Value Paare erzeugen, kann CouchDB sie nach Schlüssel sortiert in die B-Tree Storage Engine einfügen. In O Notation in O(log N) beziehungsweise O(log N + K).
In CouchDB greift man auf Dokumente und Views über Schlüssel oder Schlüsselbereiche zu. Das ist eine direkte Abbildung der Operationen, die von CouchDBs B-Tree Storage Engine ausgeführt werden. Zusammen mit den Operationen für das Einfügen und Aktualisieren von Dokumenten sind es diese Funktionen, die uns das CouchDB API als eine dünne Schicht um den Datenbankkern beschreiben lassen.
Allein schon die Beschränkung, dass auf Ergebnisse ausschließlich per Schlüssel zugegriffen werden kann, führt zu massiven Steigerungen der Zugriffsgeschwindigkeit. Neben diesen Geschwindigkeitsvorteilen können die Daten noch über verschiedene Knoten partitioniert werden, ohne die Möglichkeit zu verlieren, jeden Knoten isoliert zu verwenden. BigTable, Hadoop, SimpleDB und memcached erlauben ausschließlich eine Suche nach Schlüssel aus genau diesen Gründen.
Eine Tabelle in einer relationalen Datenbank ist eine große einzelne Datenstruktur. Wenn man eine Tabelle ändern möchte, um beispielsweise eine Zeile zu aktualisieren, muss sichergestellt sein, dass niemand versucht, die selbe Zeile zur gleichen Zeit zu ändern. Des weiteren müssen Lesezugriffe für diese Zeile unterbunden werden. Üblicherweise wird das durch ein Lock erreicht. Wenn mehrere Clients gleichzeitig auf die Tabelle zugreifen, erhält der erste Client das Lock und sorgt so dafür, dass alle anderen warten müssen. Wenn der erste Client seine Anfrage beendet hat, erhält der nächste Client das Lock usw. Diese Serialisierung der Anfragen, selbst wenn sie gleichzeitig ankommen, benötigt eine erhebliche Menge an Rechenzeit. Unter großer Last kann es vorkommen, dass eine relationale Datenbank mehr damit beschäftigt ist herauszufinden, was in welcher Reihenfolge zu tun ist, als die Anfragen zu beantworten.
Anstelle von Locks verwendet CouchDB Multi-Version Concurrency Control (MVCC) um den konkurrierenden Zugriff auf die Datenbank zu verwalten. Abbildung 3: MVCC bedeutet kein Locking veranschaulicht die Unterschiede zwischen MVCC und traditionellen Locking Mechanismen. MVCC bedeutet, dass CouchDB mit voller Geschwindigkeit arbeiten kann — selbst unter hoher Last. Anfragen werden parallel beantwortet und nutzen so jedes Quäntchen Rechenleistung aus, das Server zu bieten hat.
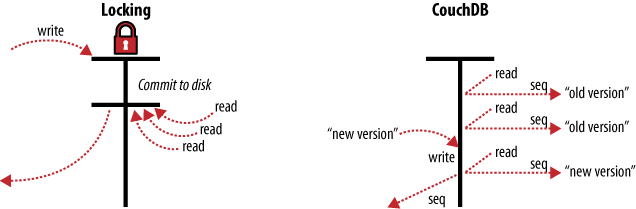
Abbildung 3: MVCC bedeutet kein Locking
Dokumente in CouchDB werden versioniert, ähnlich zu Versionskontrollsystemen wie Subversion. Wenn man einen Wert in einem Dokument ändern möchte, erzeugt man eine neue Version des Dokuments und speichert es neben dem alten. Anschließend hat man zwei Versionen des Dokuments — eine alte und eine neue.
Warum sollte das besser sein als Locking? Nehmen wir eine Gruppe von Anfragen für ein bestimmtes Dokument. Die erste Anfrage liest das Dokument. Während diese Anfrage bearbeitet wird, ändert die zweite Anfrage das Dokument. Da die zweite Anfrage eine komplett neue Version des Dokuments anlegt, kann CouchDB diese Version einfach an die Datenbank anhängen, ohne darauf zu warten, dass die erste Anfrage beendet wurde.
Wenn eine dritte Anfrage das gleiche Dokument lesen möchte, wird CouchDB auf die neue Version verweisen, die gerade eben erzeugt wurde. Während der ganzen Zeit könnte die erste Anfrage immer noch damit beschäftigt sein, die ursprüngliche Version zu lesen.
Während eines Lesezugriffs wird immer der zu dem Zeitpunkt aktuellste Zustand der Datenbank verwendet.
Anwendungsentwickler müssen berücksichtigen, welche Eingaben akzeptabel sind und welche nicht. Die Möglichkeiten von relationalen Datenbanken, komplexe Daten innerhalb der Datenbank zu überprüfen, sind beschränkt. CouchDB bietet dagegen mächtige Funktionen um Dokumente innerhalb der Datenbank zu validieren.
CouchDB kann Dokumente mithilfe von JavaScript validieren. Diese Funktionen sind ganz ähnlich zu den MapReduce Funktionen. Jedesmal wenn ein Dokument verändert werden soll, wird CouchDB eine Kopie des aktuellen und eine Kopie des neuen Dokuments zusammen mit einigen zusätzlichen Informationen wie Benutzer und Authentifizierungsdetails an die Validierungsfunktion übergeben. Diese hat nun die Möglichkeit die Änderung zu erlauben oder abzulehnen.
In dem man CouchDB für sich arbeiten und diese Überprüfungen durchführen lässt, spart man unglaublich viel Aufwand und Rechenzeit, die sonst für die Serialisierung von Objektgraphen via SQL und die Umwandlung in Domainobjekte benutzt würde, um die Validierung schließlich in der Anwendung durchzuführen.
Daten innerhalb eines einzelnen Datenbankknotens konsistent zu halten, ist für die meisten Datenbanken relativ einfach. Die Schwierigkeiten beginnen, wenn Konsistenz über mehrere Datenbankserver sichergestellt werden soll. Wenn ein Client einen Schreibzugriff auf Server A macht, wie stellt man sicher, dass Server B, C oder D konsistent sind? Das ist für relationale Datenbanken ein ziemlich komplexes Problem, dessen Lösung ganze Bücher füllt. Man kann zwischen Multi-Master, Master/Slave, Partitionierung, Sharding, Write-Through Caches und vielen anderen Ansätzen wählen.
CouchDB führt Operationen immer im Kontext eines einzelnen Dokuments aus. Da CouchDB letztendlich die Konsistenz zwischen verschiedenen Datenbanken mittels inkrementeller Replikation wieder herstellt, muss man sich keine Gedanken mehr darüber machen, ob die Verbindung zwischen den verschiedenen Servern auch permanent besteht. Inkrementelle Replikation ist ein Prozess bei dem Änderungen an Dokumenten periodisch zwischen den Servern kopiert werden. Damit ist es möglich einen sogenannten Shared Nothing Cluster von Datenbanken einzurichten, in dem jeder Knoten unabhängig ist und keinen Single Point of Failure darstellt.
Muss der CouchDB Datenbank Cluster nach oben skaliert werden? Dann stellt man einfach einen Server dazu.
Wie in Abbildung 4: Inkrementelle Replikation zwischen CouchDB Knoten dargestellt wird, synchronisiert die inkrementelle Replikation von CouchDB die Daten zwischen zwei beliebigen Datenbanken wann und wie auch immer man möchte. Nach der Replikation kann jede Datenbank unabhängig von der anderen arbeiten.
Man kann dieses Feature beispielsweise dazu nutzen, Datenbanken innerhalb eines Clusters oder zwischen Rechenzentren mit einem Cron Job zu synchronisieren. Oder man synchronisiert die Daten mit dem eigenen Laptop um später offline weiter arbeiten zu können. Jede Datenbank kann ganz normal benutzt werden und Änderungen an den Daten können später in beide Richtungen synchronisiert werden.
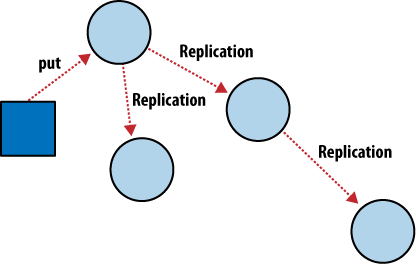
Abbildung 4: Inkrementelle Replikation zwischen CouchDB Knoten
Was passiert, wenn man das gleiche Dokument in zwei verschiedenen Datenbanken ändert und anschließend die Datenbanken synchronisieren möchte? CouchDBs Replikationssystem hat eine automatische Konflikterkennung und Konfliktauflösung. Wenn CouchDB erkennt, dass ein Dokument in beiden Datenbanken geändert wurde, wird es als konfliktbehaftet markiert — genau wie in einem normalen Versionskontrollsystem.
Das ist nicht so ein großes Problem wie es zunächst scheinen mag. Wenn zwei Versionen des gleichen Dokuments kollidieren, wird die Version, die gewinnt als aktuelles Dokument gespeichert. Die Version, die verloren hat, wird nicht vergessen, sondern als voherige Version gespeichert, so dass man darauf zugreifen kann, wenn man möchte. Das geschieht automatisch und konsistent in beiden Datenbanken auf die gleiche Weise.
Es ist Aufgabe des Entwicklers zu entscheiden, wie ein Konflikt am besten zu lösen ist. Beide Versionen können in der Datenbank bleiben, es wird zur alten Version zurückgekehrt oder die Anwendung versucht den Konflikt aufzulösen und eine neue Version zu speichern.
Ein Freund und Kollege, Greg Borenstein, hat eine kleine Bibliothek entwickelt, die Songbird Wiedergabelisten in JSON Objekte wandelt. Um die Objekte in einer Backup Anwendung zu speichern verwendet er CouchDB. Die fertige Anwendung verwendet CouchDBs MVCC und versionierte Dokumente um sicherzustellen, dass die Songbird Wiedergabelisten korrekt zwischen verschiedenen Rechnern gesichert werden.
Songbird ist ein freier Software Media Player mit einem integrierten Webbrowser, der auf der Mozilla XULRunner Plattform basiert. Songbird gibt es für Microsoft Windows, Apple Mac OS X, Solaris und Linux.
Wenn man den Ablauf der Songbird Backup Anwendung genauer untersucht, stellt man fest, dass der Benutzer zunächst ein Backup der Wiedergabelisten auf einem der Computer erstellt. Anschließend benutzt er Songbird, um diese Wiedergabelisten zwischen verschiedenen Computern zu synchronisieren. Wir werden sehen, wie ein vermeintlich kniffliges Problem einfach so funktioniert.
Beim ersten Mal werden die Wiedergabelisten der Anwendung übergeben und ein Backup wird gestartet. Jede Wiedergabeliste wird in ein JSON Objekt umgewandelt und an eine CouchDB Datenbank übergeben. Wie in Abbildung 5: Backup in eine einzelne Datenbank zeigt, liefert CouchDB die ID des Dokuments und die Versionsnummer jeder Wiedergabeliste zurück, während die JSON Objekte in der Datenbank gespeichert werden.
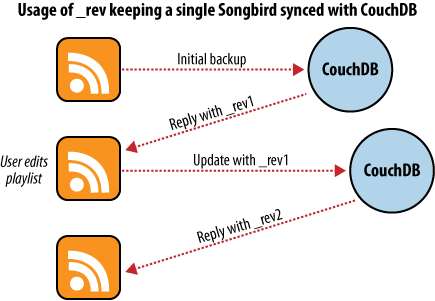
Abbildung 5: Backup in eine einzelne Datenbank
Nach ein paar Tagen haben sich die Wiedergabelisten geändert und sollen wieder gesichert werden. Nachdem wir die Wiedergabelisten der Backup Anwendung übergeben haben, holt die sich die letzte Version von CouchDB zusammen mit der aktuellen Version des Dokuments. Beim anschließenden Aktualisieren des Dokuments, muss die Versionsnummer wieder mit übergeben werden.
CouchDB stellt dann sicher, dass die übergebene Versionsnummer tatsächlich der aktuellsten Version des Dokuments entspricht. Weil CouchDB die Versionsnummer bei jeder Änderung ebenfalls anpasst, bedeutet ein Unterschied, dass jemand in der Zwischenzeit das Dokument geändert hat. In den allermeisten Fällen ist es dann keine gute Idee das Dokument zu speichern, ohne sich die Änderungen vorher anzusehen.
Der Zwang, beim Speichern die korrekte Versionsnummer des Dokuments zu übergeben, ist der Kern von CouchDBs Optimistic Concurrency.
Wenn wir einen Laptop haben und mit dem Deskop Computer synchron bleiben wollen, ist der erste Schritt das "Wiederherstellen einer Sicherung". Da dies das erste Mal ist, sollte der Laptop im Anschluß daran eine exakte Kopie der Wiedergabelisten haben.
Nachdem die Wiedergabeliste für Argentinische Tangos auf dem Laptop geändert wurde und wir ein paar neue Songs gekauft haben, sollen die Änderungen gespeichert werden. Die Backup Anwendung speichert die Änderungen in der CouchDB auf dem Laptop und erzeugt eine neue Version des Dokuments. Ein paar Tage später erinnern wir uns und möchten die Wiedergabelisten mit dem Desktop Computer synchronisieren. Wie in Abbildung 6: Synchronisation zwischen zwei Datenbanken gezeigt wird, kopiert die Backup Anwendung das neue Dokument und die neue Version in die CouchDB auf dem Desktop Computer. Beide Computer haben nun die gleiche Version des Dokuments.
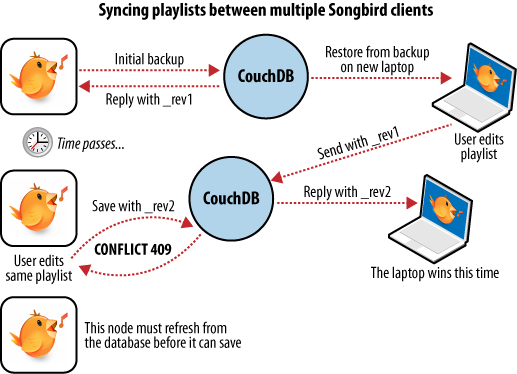
Abbildung 6: Synchronisation zwischen zwei Datenbanken
Weil CouchDB die Versionen von Dokumenten mitverfolgt, stellt es sicher, dass Änderungen wie diese einfach funktionieren. Wären die Wiedergabeliste auf beiden Seiten zwischen den Backups geändert worden, sähe die Sache anders aus.
Wir sichern einige Änderung auf dem Laptop und vergessen zu synchronisieren. Ein paar Tage später, als wir gerade Wiedergabelisten auf dem Desktop Rechner ändern, machen wir ein Backup und wollen dies mit dem Laptop synchronisieren. Wie Abbildung 7: Synchronisierungskonflikte zwischen zwei Datenbanken zeigt, erkennt CouchDB den Konflikt und ist so nett und informiert uns.
Dieser Konflikt ist in der Anwendung leicht zu lösen. Man lädt die Version aus der CouchDB und vergleicht sie mit der lokalen Version. Anschließend bietet man dem Nutzer die Möglichkeit die Änderungen entweder zusammenzuführen oder die lokalen Änderungen in einer neuen Wiedergabeliste zu speichern.
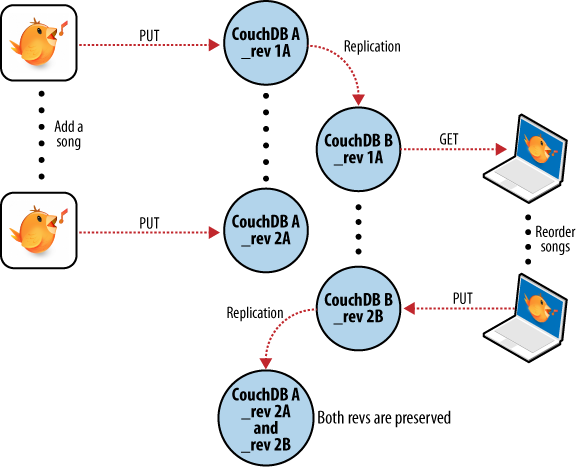
Abbildung 7: Synchronisierungskonflikte zwischen Datenbanken
Das Design von CouchDB ist stark an die Architektur des Webs angelehnt und von den Erkenntnissen beim Bau von massiv verteilten Systemen inspiriert. Indem man versteht, warum diese Architektur so arbeitet wie sie es tut und durch Erkennen welche Teile einer Anwendung leicht verteilt werden können und welche nicht, schafft man die Möglichkeit, verteilte und skalierbare Anwendungen zu entwickeln. Mit CouchDB oder auch ohne.
Die Kernpunkte des Konsistenzmodells von CouchDB wurden besprochen und auf einige Vorteile hingewiesen, die man damit erreichen kann, wenn man mit CouchDB arbeitet anstatt dagegen. Doch genug der Theorie — fangen wir endlich an!