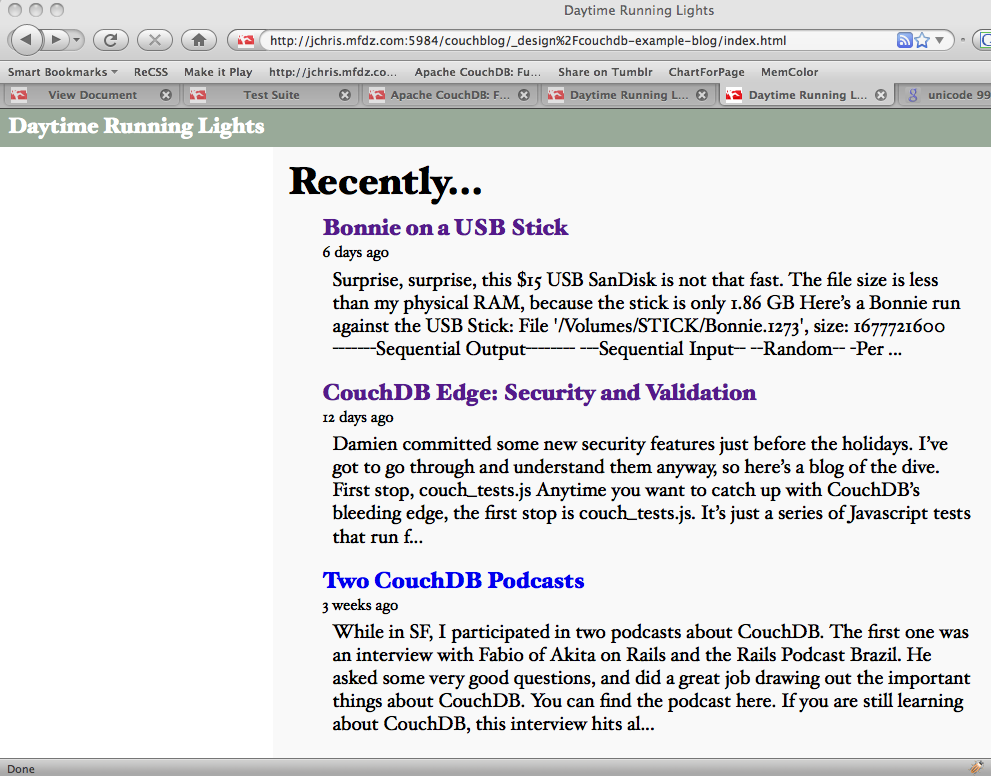
Figure 1. La page d’accueil ainsi générée
Les derniers chapitres visaient à insérer et extraire des données de CouchDB. Vous avez appris à modéliser vos données dans des documents et à les récupérer à l’aide de l’API HTTP. Dans ce chapitre, nous verrons comment utiliser le mécanisme de vues pour générer la page d’accueil de Sofa. Nous verrons aussi comment la fonction de listage génère la représentation HTML ou XML en fonction de la demande du client.
Puisque nous avons désormais créé un article de blogue et que nous pouvons l’afficher au format HTML, nous allons nous attaquer à la page d’accueil ; là où débarquent nos visiteurs. Cette page exhibera la liste des dix derniers articles publiés, avec leur titre et un bref résumé. La première étape consiste à écrire la fonction MapReduce qui construit l’index exploité par CouchDB lors de la requête pour y trouver les articles selon leur date de publication.
À l’occasion du chapitre 6, Trouver vos données à l’aide des vues, nous avons souligné que nous pouvions nous passer de la fonction d’agrégation (reduce en anglais) pour les requêtes basiques. Or, pour notre page d’accueil, nous voulons simplement trier les articles par date de publication ; nous n’avons donc pas besoin de cette fonction : la fonction de subdivision (map en anglais) y parvient seule.
Vous êtes ainsi paré à rédiger la fonction d’agrégation qui bâtit la liste de tous les articles. L’objectif de cette vue est simple : trier ces articles par date de publication.
Ci-dessous se trouve le code source de la fonction d’affichage. Nous nous arrêterons sur les points essentiels.
function(doc) {
if (doc.type == "post") {
La première chose consiste à s’assurer que le document que nous traitons est un article. En effet, nous ne voulons pas que les commentaires se retrouvent en page d’accueil. La condition doc.type == "post" est vraie uniquement pour les articles. Dans le chapitre 7, Fonctions de validation, nous avons vu que la fonction de validation nous garantit une certaine structure d’un article dans le but de nous aider à les afficher sur la page d’accueil.
var summary = (doc.html.replace(/<(.|\n)*?>/g, '').substring(0,350) + '...');
Cette ligne tronque le code HTML de l’article (transcrit du format Markdown avant d’être sauvegardé) et élimine la plupart des tags et des images ; du moins, il l’épure suffisamment pour un affichage convenable sur notre page d’accueil.
La section suivante est le passage clé de la vue. Nous émettons, pour chaque document, une clé (doc.created_at) et une valeur. La clé est utilisée pour le tri et générée de sorte à pouvoir extraire rapidement les articles correspondants à une époque donnée.
emit(doc.created_at, {
html : doc.html,
summary : summary,
title : doc.title,
author : doc.author
});
La valeur que nous avons émise est un objet JavaScript qui contient une partie des champs du document ainsi que le résumé que nous venons de générer. Il vaut mieux éviter d’émettre l’intégralité du document. Nous vous recommandons de garder vos vues aussi légères que possible. Aussi, n’émettez que les données que vous comptez utiliser dans votre application. Dans note cas, nous émettons le résumé (pour la page d’accueil), le code HTML (pour le flux Atom), le titre de l’article et son auteur.
} };
Vous devriez maintenant être à même de comprendre cette fonction de subdivision (map en anglais). L’appel à emit() crée une entrée dans la vue pour chaque article. Nous nommons cette vue recent-posts.
{
"_design/sofa",
"views": {
"recent-posts": {
"map": "function(doc) { if (doc.type == "post") { ... code to emit posts ... }"
}
}
"_attachments": {
...
}
}
CouchApp se charge de fusionner vos fichiers locaux en un seul design document JSON, ce qui nous permet d’écrire notre vue dans le fichier views/recent-posts/map.js. Une fois que la fonction d’agrégation est intégrée au design document, notre vue est prête à l’emploi : nous pourrons y récupérer les dix derniers articles. Bien sûr, cela ressemble beaucoup à l’affiche d’un unique article. La seule différence notable est que nous obtenons désormais un tableau d’objets JSON au lieu d’un seul objet JSON.
La requête GET vers l’URI est :
/blog/_design/sofa/_view/recent-posts
Une vue décrite dans le document /database/_design/designdocname dans le champ views peut être appelée à l’adresse /database/_design/designdocname/_view/viewname.
Vous pouvez passer des arguments à votre requête HTTP. Dans notre cas :
descending: true, limit: 5
De cette manière, nous obtenons les cinq derniers articles.
L’URL est donc la suivante :
/blog/_design/sofa/_view/recent-posts?descending=true&limit=5
La fonction _list a été détaillée dans le Chapitre 5, Design Documents. Dans notre cas, nous utiliserons une fonction de listage JavaScript pour générer les formes HTML et XML à partir de la vue relatant les articles récents. Le serveur de vues JavaScript livré avec CouchDB est capable de baser sa réponse sur le résultat de la négociation HTTP et sur le contenu de l’en-tête Accept.
La fonction _list de l’API reçoit un enregistrement à la fois et envoie le résultat de la transcription au navigateur par paquet.
Penchons-nous sur la fonction de listage de Sofa. C’est une fonction assez longue qui introduit de nouveaux concepts. Aussi, nous avancerons lentement pour nous assurer de détailler les éléments d’importance.
function(head, req) {
// !json templates.index
// !json blog
// !code vendor/couchapp/path.js
// !code vendor/couchapp/date.js
// !code vendor/couchapp/template.js
// !code lib/atom.js
La définition de la fonction déclare attendre deux arguments, head et req. Nous n’utilisons pas head, mais uniquement req. Ce dernier qualifie la requête du client et détient ses en-têtes ainsi que la chaîne décrivant la ressource demandée (query string dans le jargon anglais). Les premières lignes de la fonction sont des macros CouchApp qui injectent du code et des données à partir d’autres fichiers du design document. Celles-ci ont été décrites dans le Chapitre 11, Gestion des design documents et permettent, en résumé, de conserver un code clair. Notre fonction de listage exploite les assistants JavaScript CouchApp pour la génération des URL (path.js), pour la gestion des dates (date.js) et pour l’exploitation des modèles de documents permettant de générer le code HTML.
var indexPath = listPath('index','recent-posts',{descending:true, limit:5});
var feedPath = listPath('index','recent-posts',{descending:true, limit:5, format:"atom"});
Les deux lignes suivantes permettent de générer les URL vers la page d’accueil et vers le flux Atom correspondant. La fonction listPath se trouve définie dans path.js ; elle sait comment générer les liens vers les listes gérées par le design document qui l’appelle.
Le bloc suivant produit le code HTML destiné au blogue. Reportez-vous au Chapitre 8, Fonctions d’affichage pour le détail de l’API exploitée ici. En bref, les clients peuvent indiquer le format qu’ils préfèrent dans l’en-tête HTTP Accept ou par le paramètre format positionné dans la requête. Sur le serveur, nous indiquons quels sont les formats que nous pouvons fournir et leur associons un ordre de priorité. Ainsi, si le client accepte plusieurs formats, le premier qui a été indiqué est choisi. À noter qu’il n’est pas rare que les navigateurs déclarent accepter de nombreux formats, aussi veillez à placer le HTML au sommet des priorités. À défaut, vous pourriez envoyer du XML à un navigateur s’attendant à recevoir du HTML.
provides("html", function() {
La fonction provides nécessite deux arguments : le nom du format (parmi une liste de types MIME connus) et une fonction chargée de produire le format correspondant. Notez bien que tous les appels à send et getRow doivent se faire dans la fonction provides. Bref, regardons comment le code HTML est effectivement généré :
send(template(templates.index.head, {
title : blog.title,
feedPath : feedPath,
newPostPath : showPath("edit"),
index : indexPath,
assets : assetPath()
}));
La première chose que nous observons est l’appel au moteur de patronage en lui donnant le nom du blogue et quelques URL relatives. La fonction de patronage utilisée par Sofa est assez simple : elle substitue les variables prépositionnées par les valeurs qui lui sont communiquées. Ici, le patron est stocké dans la variable templates.index.head qui a été importée par la macro CouchApp du début. Le deuxième argument transmis à la fonction de patronage contient toutes les valeurs à insérer dans le patron, soit title, feedPath, newPostPath, index, et assets. Nous reviendrons plus tard sur le patron en lui-même. Pour lors, il suffit de savoir qu’il est stocké dans la variable templates.index.head et qu’il génère la partie supérieure de la page HTML, laquelle ne dépend pas du contenu de la vue comportant les articles récents.
Maintenant que l’en-tête de la page est généré, il est temps d’itérer sur les articles pour les publier un à un. Tout d’abord, déclarons nos variables et notre boucle :
var row, key;
while (row = getRow()) {
var post = row.value;
key = row.key;
La variable row stocke chaque enregistrement (tuple) JSON de la vue tel qu’il est transmis à notre fonction. Quant à la variable key, nous la conservons jusqu’à la dernière itération où elle servira à produire le lien vers la page suivante.
send(template(templates.index.row, {
title : post.title,
summary : post.summary,
date : post.created_at,
link : showPath('post', row.id)
}));
}
Puisque nous avons stocké le tuple et sa clé, nous pouvons appeler le moteur de patronage pour produire le code correspondant. Cette fois-ci, le patron se trouve dans templates.index.row et attend l’intitulé de l’article, l’URL de sa page, son résumé (que nous avons généré avec notre fonction de subdivision en créant la vue) et sa date de publication.
Une fois que nous avons traité l’ensemble des articles devant être inclus dans notre liste, nous pouvons la clôturer et achever la production de la page. La dernière chaîne de caractères n’a pas besoin d’être envoyée au client par la fonction send() : elle peut être retournée par notre fonction. Mis à part ce détail, la production du bas de page devrait vous être familière.
return template(templates.index.tail, {
assets : assetPath(),
older : olderPath(key)
});
});
Une fois que le bas de page a été retourné, nous fermons la fonction de génération du code HTML. Si nous ne désirions pas fournir un flux Atom, nous aurions fini ici. Toutefois, nous savons pertinemment que la plupart de nos lecteurs accèderont au blogue par un agrégateur de flux, aussi cette fonctionnalité est vitale.
provides("atom", function() {
La fonction de génération du flux Atom est définie de la même manière que son homologue HTML : nous recourrons à la fonction provides() avec la clé du type MIME. La structure de la fonction Atom est identique à la précédente : un en-tête, une boucle pour les articles et un bas de page.
// we load the first row to find the most recent change date
var row = getRow();
La différence avec la fonction HTML est que, dans le cas de l’Atom, il est nécessaire de connaître la date de dernière modification du blogue. Cette information devrait correspondre au premier tuple de notre liste. Aussi, nous le chargeons sans l’afficher, avant que toute donnée soit envoyée au client (à l’exception des en-têtes HTTP définis quand la fonction provides capture le format), et l’utilisons pour remplir le champ last-updated.
// generate the feed header
var feedHeader = Atom.header({
updated : (row ? new Date(row.value.created_at) : new Date()),
title : blog.title,
feed_id : makeAbsolute(req, indexPath),
feed_link : makeAbsolute(req, feedPath),
});
La fonction Atom.header est définie dans lib/atom.js, qui a été importée par les premières lignes de notre fonction. Cette bibliothèque exploite l’extension JavaScript E4X pour générer le flux XML.
// send the header to the client
send(feedHeader);
Puisque les en-têtes du flux ont été générés, nous les envoyons au client à l’aide de la fonction send(). C’en est alors fini des en-têtes et nous pouvons produire chaque élément du flux à partir d’un tuple de la vue. Nous utilisons ici une boucle légèrement différente de celle de tantôt puisque nous avons déjà chargé le premier enregistrement pour générer les en-têtes.
// loop over all rows
if (row) {
do {
La boucle JavaScript do/while ressemble à la boucle while utilisée par la fonction HTML, à la différence notable qu’elle sera exécutée au moins une fois. Ceci car le test de la condition d’itération se fait après avoir exécuté le corps de la boucle. Nous pouvons ainsi générer l’entrée correspondant à l’article que nous avons chargé en mémoire au début avant d’appeler la fonction getRow() pour charger le suivant.
// generate the entry for this row
var feedEntry = Atom.entry({
entry_id : makeAbsolute(req, '/' +
encodeURIComponent(req.info.db_name) +
'/' + encodeURIComponent(row.id)),
title : row.value.title,
content : row.value.html,
updated : new Date(row.value.created_at),
author : row.value.author,
alternate : makeAbsolute(req, showPath('post', row.id))
});
// send the entry to client
send(feedEntry);
La génération des éléments exploite aussi la bibliothèque Atom définie dans atom.js. Il y a une différence notable entre les éléments d’une liste HTML et ceux d’un flux Atom. Dans le premier cas, nous n’affichons que le résumé de l’article tandis que, dans le second, nous produisons l’ensemble de l’article. En substituant, pour content, row.value.html à row.value.summary, vous pourriez publier uniquement le résumé, ce qui aurait pour effet de contraindre vos visiteurs à cliquer sur l’article pour le consulter.
} while (row = getRow());
}
Comme nous l’avons expliqué plus tôt, ce type de boucle repousse l’évaluation de la condition d’itération à la fin de la boucle, d’où il suit que le prochain tuple n’est chargé qu’à la fin de la boucle.
// close the loop after all rows are rendered
return "</feed>";
});
};
Une fois que tous les enregistrements ont été parcourus, nous clôturons le flux en fermant la balise XML et en l’envoyant au client.
La Figure 1, La page d’accueil ainsi générée illustre le résultat.
Figure 1. La page d’accueil ainsi générée
Ceci est notre liste des articles du blogue. Ce n’est pas si difficile, n’est-ce pas ? Nous avons désormais la page d’accueil, savons récupérer un seul document tout comme toute une vue et nous avons comment transmettre des arguments aux vues.