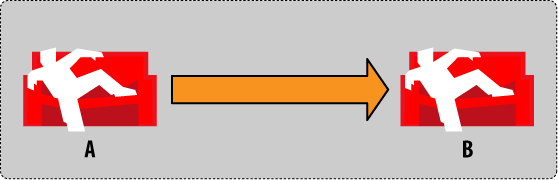
Figure 1. Conflict management by example: step 1
Suppose you are sitting in a coffee shop working on your book. J. Chris comes over and tells you about his new phone. The new phone came with a new number, and you have J. Chris dictate it while you change it using your laptop’s address book application.
Luckily, your address book is built on CouchDB, so when you come home, all you need to do to get your home computer up-to-date with J. Chris’s number is replicate your address book from your laptop. Neat, eh? What’s more, CouchDB has a mechanism to maintain continuous replication, so you can keep a whole set of computers in sync with the same data, whenever a network connection is available.
Let’s change the scenario a little bit. Since J. Chris didn’t anticipate meeting you at the coffee shop, he also sent you an email with the new number. At the time you weren’t using WiFi because you wanted to concentrate on your work, so you didn’t read his email until you got home. But it was a long day and by then you had forgotten that you changed the number in the address book on your laptop. When you read the email at home, you simply copy-and-pasted the number into the address book on your home computer. Now—and here’s the twist—it turns out you entered the wrong number in your laptop’s address book.
You now have a document in each of the databases that has different information. This situation is called a conflict. Conflicts occur in distributed systems. They are a natural state of your data. How does CouchDB’s replication system deal with conflicts?
When you replicate two databases in CouchDB and you have conflicting changes, CouchDB will detect this and will flag the affected document with the special attribute "_conflicts":true. Next, CouchDB determines which of the changes will be stored as the latest revision (remember, documents in CouchDB are versioned). The version that gets picked to be the latest revision is the winning revision. The losing revision gets stored as the previous revision.
CouchDB does not attempt to merge the conflicting revision. Your application dictates how the merging should be done. The choice of picking the winning revision is arbitrary. In the case of the phone number, there is no way for a computer to decide on the right revision. This is not specific to CouchDB; no other software can do this (ever had your phone’s sync-contacts tool ask you which contact from which source to take?).
Replication guarantees that conflicts are detected and that each instance of CouchDB makes the same choice regarding winners and losers, independent of all the other instances. There is no group decision made; instead, a deterministic algorithm determines the order of the conflicting revision. After replication, all instances taking part have the same data. The data set is said to be in a consistent state. If you ask any instance for a document, you will get the same answer regardless which one you ask.
Whether or not CouchDB picked the version that your application needs, you need to go and resolve the conflict, just as you need to resolve a conflict in a version control system like Subversion. Simply create a version that you want to be the latest by either picking the latest, or the previous, or both (by merging them) and save it as the now latest revision. Done. Replicate again and your resolution will populate over to all other instances of CouchDB. Your conflict resolving on one node could lead to further conflicts, all of which will need to be addressed, but eventually, you will end up with a conflict-free database on all nodes.
This is an interesting conflicts scenario in that we helped a BBC build a solution for it that is now in production. The basic setup is this: to guarantee that the company’s website is online 24/7, even in the event of the loss of a data center, it has multiple data centers backing up the website. The “loss” of a data center is a rare occasion, but it can be as simple as a network outage, where the data center is still alive and well but can’t be reached by anyone.
The “split brain” scenario is where two (for simplicity’s sake we’ll stick to two) data centers are up and well connected to end users, but the connection between the data centers—which is most likely not the same connection that end users use to talk to the computers in the data center—fails.
The inter data center connection is used to keep both centers in sync so that either one can take over for the other in case of a failure. If that link goes down, you end up with two halves of a system that act independently—the split brain.
As long as all end users can get to their data, the split brain is not scary. Resolving the split brain situation by bringing up the connection that links the data centers and starting synchronization again is where it gets hairy. Arbitrary conflict resolution, like CouchDB does by default, can lead to unwanted effects on the user’s side. Data could revert to an earlier stage and leave the impression that changes weren’t reliably saved, when in fact they were.
Let’s go through an illustrated example of how conflicts emerge and how to solve them in super slow motion. Figure 1, “Conflict management by example: step 1” illustrates the basic setup: we have two CouchDB databases, and we are replicating from database A to database B. To keep this simple, we assume triggered replication and not continuous replication, and we don’t replicate back from database B to A. All other replication scenarios can be reduced to this setup, so this explains everything we need to know.
Figure 1. Conflict management by example: step 1
We start out by creating a document in database A (Figure 2, “Conflict management by example: step 2”). Note the clever use of imagery to identify a specific revision of a document. Since we are not using continuous replication, database B won’t know about the new document for now.
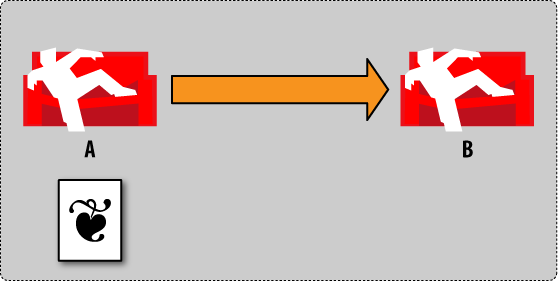
Figure 2. Conflict management by example: step 2
We now trigger replication and tell it to use database A as the source and database B as the target (Figure 3, “Conflict management by example: step 3”). Our document gets copied over to database B. To be precise, the latest revision of our document gets copied over.
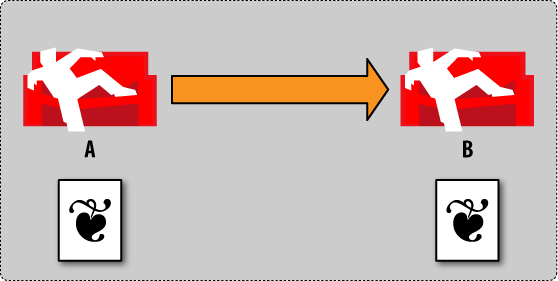
Figure 3. Conflict management by example: step 3
Now we go to database B and update the document (Figure 4, “Conflict management by example: step 4”). We change some values and upon change, CouchDB generates a new revision for us. Note that this revision has a new image. Node A is ignorant of any activity.
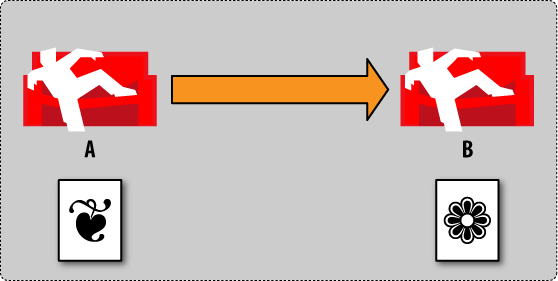
Figure 4. Conflict management by example: step 4
Now we make a change to our document in database A by changing some other values (Figure 5, “Conflict management by example: step 5”). See how it makes a different image for us to see the difference? It is important to note that this is still the same document. It’s just that there are two different revisions of that same document in each database.
Figure 5. Conflict management by example: step 5
Now we trigger replication again from database A to database B as before (Figure 6, “Conflict management by example: step 6”). By the way, it doesn’t make a difference if the two databases live in the same CouchDB server or on different servers connected over a network.
Figure 6. Conflict management by example: step 6
When replicating, CouchDB detects that there are two different revisions for the same document, and it creates a conflict (Figure 7, “Conflict management by example: step 7”). A document conflict means that there are now two latest revisions for this document.
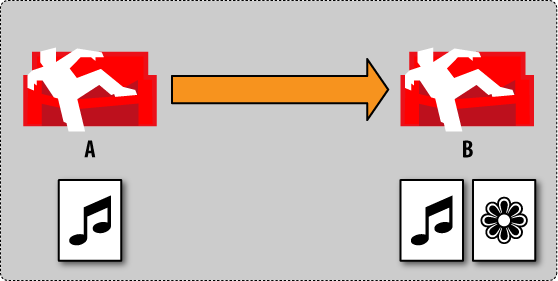
Figure 7. Conflict management by example: step 7
Finally, we tell CouchDB which version we would like to be the latest revision by resolving the conflict (Figure 8, “Conflict management by example: step 8”). Now both databases have the same data.

Figure 8. Conflict management by example: step 8
Other possible outcomes include choosing the other revision and replicating that decision back to database A, or creating yet another revision in database B that includes parts of both conflicting revisions (a merge) and replicating that back to database A.
Now that we’ve walked through replication with pretty pictures, let’s get our hands dirty and see what the API calls and responses for this and other scenarios look like. We’ll be continuing Chapter 4, The Core API by using curl on the command line to make raw API requests.
First, we create two databases that we can use for replication. These live on the same CouchDB instance, but they might as well live on a remote instance—CouchDB doesn’t care. To save us some typing, we create a shell variable for our CouchDB base URL that we want to talk to. We then create two databases, db and db-replica:
HOST="http://127.0.0.1:5984"
> curl -X PUT $HOST/db
{"ok":true}
> curl -X PUT $HOST/db-replica
{"ok":true}
In the next step, we create a simple document {"count":1} in db and trigger replication to db-replica:
> curl -X PUT $HOST/db/foo -d '{"count":1}'
{"ok":true,"id":"foo","rev":"1-74620ecf527d29daaab9c2b465fbce66"}
> curl -X POST $HOST/_replicate -d '{"source":"db","target":"http://127.0.0.1:5984/db-replica"}'
{"ok":true,...,"docs_written":1,"doc_write_failures":0}]} -H "Content-Type: application/json"
We skip a bit of the output of the replication session (see Chapter 16, Replication for details). If you see "docs_written":1 and "doc_write_failures":0, our document made it over to db-replica. We now update the document to {"count":2} in db-replica. Note that we now need to include the correct _rev property.
> curl -X PUT $HOST/db-replica/foo -d '{"count":2,"_rev":"1-74620ecf527d29daaab9c2b465fbce66"}'
{"ok":true,"id":"foo","rev":"2-de0ea16f8621cbac506d23a0fbbde08a"}
Next, we create the conflict! We change our document on db to {"count":3}. Our document is now logically in conflict, but CouchDB doesn’t know about it until we replicate again:
> curl -X PUT $HOST/db/foo -d '{"count":3,"_rev":"1-74620ecf527d29daaab9c2b465fbce66"}'
{"ok":true,"id":"foo","rev":"2-7c971bb974251ae8541b8fe045964219"}
> curl -X POST $HOST/_replicate -d '{"source":"db","target":"http://127.0.0.1:5984/db-replica"}'
{"ok":true,..."docs_written":1,"doc_write_failures":0}]} -H "Content-Type: application/json"
To see that we have a conflict, we create a simple view in db-replica. The map function looks like this:
function(doc) {
if(doc._conflicts) {
emit(doc._conflicts, null);
}
}
When we query this view, we get this result:
{"total_rows":1,"offset":0,"rows":[
{"id":"foo","key":["2-7c971bb974251ae8541b8fe045964219"],"value":null}
]}
The key here corresponds to the doc._conflicts property of our document in db-replica. It is an array listing all conflicting revisions. We see that the revision we wrote on db ({"count":3}) is in conflict. CouchDB’s automatic promotion of one revision to be the winning revision chose our first change ({"count":2}). To verify that, we just request that document from db-replica:
> curl -X GET $HOST/db-replica/foo
{"_id":"foo","_rev":"2-de0ea16f8621cbac506d23a0fbbde08a","count":2}
To resolve the conflict, we need to determine which one we want to keep.
How Does CouchDB Decide Which Revision to Use?
CouchDB guarantees that each instance that sees the same conflict comes up with the same winning and losing revisions. It does so by running a deterministic algorithm to pick the winner. The application should not rely on the details of this algorithm and must always resolve conflicts. We’ll tell you how it works anyway.
Each revision includes a list of previous revisions. The revision with the longest revision history list becomes the winning revision. If they are the same, the _rev values are compared in ASCII sort order, and the highest wins. So, in our example, 2-de0ea16f8621cbac506d23a0fbbde08a beats 2-7c971bb974251ae8541b8fe045964219.
One advantage of this algorithm is that CouchDB nodes do not have to talk to each other to agree on winning revisions. We already learned that the network is prone to errors and avoiding it for conflict resolution makes CouchDB very robust.
Let’s say we want to keep the highest value. This means we don’t agree with CouchDB’s automatic choice. To do this, we first overwrite the target document with our value and then simply delete the revision we don’t like:
> curl -X DELETE $HOST/db-replica/foo?rev=2-de0ea16f8621cbac506d23a0fbbde08a
{"ok":true,"id":"foo","rev":"3-bfe83a296b0445c4d526ef35ef62ac14"}
> curl -X PUT $HOST/db-replica/foo -d '{"count":3,"_rev":"2-7c971bb974251ae8541b8fe045964219"}'
{"ok":true,"id":"foo","rev":"3-5d0319b075a21b095719bc561def7122"}
CouchDB creates yet another revision that reflects our decision. Note that the 3- didn’t get incremented this time. We didn’t create a new version of the document body; we just deleted a conflicting revision. To see that all is well, we check whether our revision ended up in the document.
> curl -X GET $HOST/db-replica/foo
{"_id":"foo","_rev":"3-5d0319b075a21b095719bc561def7122","count":3}
We also verify that our document is no longer in conflict by querying our conflicts view again, and we see that there are no more conflicts:
{"total_rows":0,"offset":0,"rows":[
]}
Finally, we replicate from db-replica back to db by simply swapping source and target in our request to _replicate:
> curl -X POST $HOST/_replicate -d '{"target":"db","source":"http://127.0.0.1:5984/db-replica"}' -H "Content-Type: application/json"
We see that our revision ends up in db, too:
> curl -X GET $HOST/db/foo
{"_id":"foo","_rev":"3-5d0319b075a21b095719bc561def7122","count":3}
And we’re done.
Let’s have a look at this revision ID: 3-5d0319b075a21b095719bc561def7122. Parts of the format might look familiar. The first part is an integer followed by a dash (3-). The integer increments for each new revision the document receives. Updates to the same document on multiple instances create their own independent increments. When replicating, CouchDB knows that there are two different revisions (like in our previous example) by looking at the second part.
The second part is an md5-hash over a set of document properties: the JSON body, the attachments, and the _deleted flag. This allows CouchDB to save on replication time in case you make the same change to the same document on two instances. Earlier versions (0.9 and back) used random integers to specify revisions, and making the same change on two instances would result in two different revision IDs, creating a conflict where it was not really necessary. CouchDB 0.10 and above uses deterministic revision IDs using the md5 hash.
For example, let’s create two documents, a and b, with the same contents:
> curl -X PUT $HOST/db/a -d '{"a":1}'
{"ok":true,"id":"a","rev":"1-23202479633c2b380f79507a776743d5"}
> curl -X PUT $HOST/db/b -d '{"a":1}'
{"ok":true,"id":"b","rev":"1-23202479633c2b380f79507a776743d5"}
Both revision IDs are the same, a consequence of the deterministic algorithm used by CouchDB.
This concludes our tour of the conflict management system. You should now be able to create distributed setups that deal with conflicts in a proper way.